I am using ruODK with and ODK server on a 4-core Digital Ocean machine. ruODK is a thin wrapper around the API calls, there is no overhead from R.
I have a 4 forms with 3 submission each, each form has about 20 items - this is a really small test set. When I retrieve all items, my benchmark shows 4.66 seconds - acceptable.
When I re-run the same query with all items skipped, I had expected that the response would be immediate, but it is the same: 4.59 seconds, it is slightly faster only because nothing is stored in my local sqlite database in this run.
It looks like there is some strange inefficiency in skipping - are all data processed in both cases?
I am using SQLite as the local warehouse - what is the recommended procedure to do a "get most recent data only"? I have implemented a skip-count, but it has proven worthless.
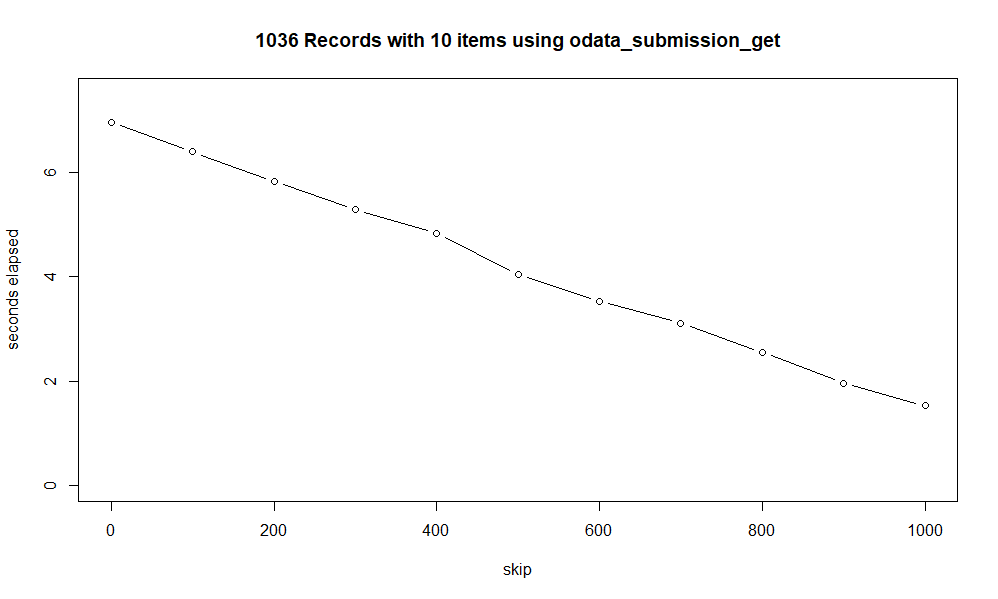
You are right, network latency was the relevant part with 1 record. This is for 1036 copies with about 10 items. Ping to DigitalOcean is 127 ms, looks like it is on the other side of the ocean.
Beautiful graph and thanks for sharing the process so others can do their own similar benchmarks!
Digital Ocean has various data centers (as do most cloud providers these days). Here is information on changing your region for an existing droplet so your data doesn't have to cross oceans.
Thanks, @LN (nice nickname, even if I found LogNaturel even better),
it's not that critical, for demonstration I am running on a free scheme anyway where I do not have much choice. The hurdle will be how to get this to run in an Intranet with https via local certificates. I wish there would be an easier choice.