Dear friends,
Many thanks to the ODK community. I have been a ODK Aggregate and now ODK central user for several years now. Currently we are collecting our Primary Eye Care and eye care survey related data using ODK central, which has around 150,300 records.
So indeed what started has a hobbyist implementation by a public health practitioner doctor with interest in health IT has now firmly taken roots in our day-to-day operations !
The last ODK central installation was done 2 years back and hasn't been touched since. I am using
ODK Central client v1.2.2
ODK Central server v1.2.1
The server is up and running on a local VMWare based VM in our institutes server stack on Ubuntu 20.04, behind common another VM running a reverse proxy. That reverse proxy serves many other subdomains as well, apart from our ODK instance.
-
- I am looking to upgrade to current versions of Central.
-
- I have taken a VM snapshot to be safe.
-
- I have also downloaded all individual forms data and XLSform definitions.
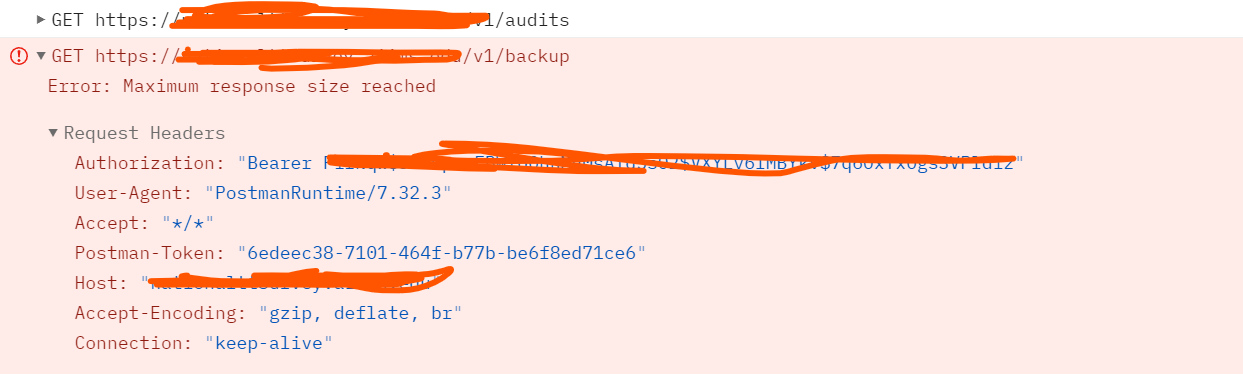
In this regard, I wanted to take a server backup using API. I am using the Postman and have managed to
- POST to the v1/session and get a Auth token
- Get list of projects
- Initiate a request to /v1/backup
However, When taking backup, I am getting an error:
"Could not get response Error: Maximum response size reached"
Query:
- How do I download and save the backup file, now that i know how to make a HTTP call
- I was able to download a backup from the web UI from https://nationalttsurvey.aiims.edu/#/system/backups That was around 4 GB compressed. Is this the same as taking a API based backup ?
- How do I backup the REDIS for Enketo
****** UPDATE
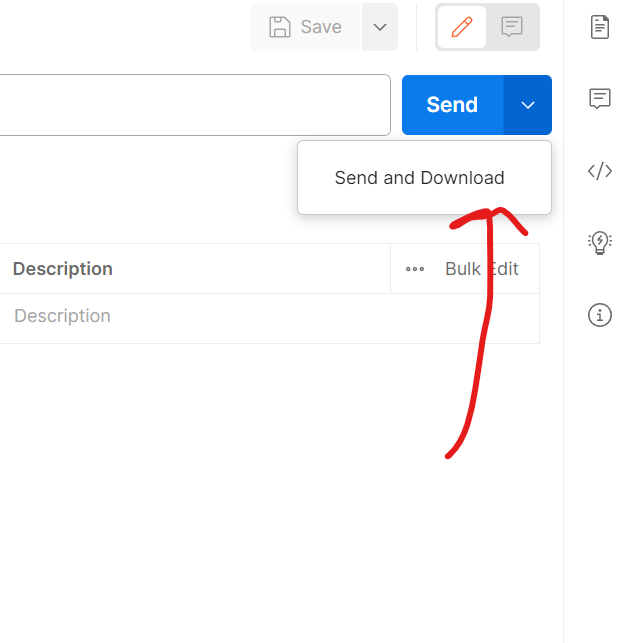
Postman gives a SEND AND DOWNLOAD option that was helpful for individual small form data download. However Postman exited on me on a gigabyte sized download in between
Many Thanks for your support
Dr Vivek Gupta, MD
1 Like
To answer my own question, I have made some headway using the following Python code
from pprint import pprint
import requests
from requests.Exceptions import HTTPError
BASEURL = 'SERVERADDRESS/v1'
EMAIL = "myUserName"
PASSWORD = "myPassword"
# GET TOKEN
try:
response = requests. Post(BASEURL + '/sessions', json={
"email": EMAIL,
"password": PASSWORD
})
response.raise_for_status()
jsonResponse = response.json()
TOKEN = jsonResponse["token"]
# print("SAVED Token")
print(TOKEN)
headers = {
'Authorization': 'Bearer ' + TOKEN,
}
# Get Number of projects
try:
response2 = requests.get(BASEURL + '/projects', headers=headers)
print(f' Response Status Code: {response2.status_code}')
jsonResponse2 = response2.json()
pprint(jsonResponse2)
except HTTPError as http_err:
print(f'HTTP error occurred: {http_err}')
except Exception as err:
print(f'Other error occurred: {err}')
# Catch Auth Errors
except HTTPError as http_err:
print(f'HTTP error occurred: {http_err}')
except Exception as err:
print(f'Other error occurred: {err}')
Now off to trying to get backup and downloading it !
Vivek
Following code to
- Use token received from an AUTH request
- Get list of all projects
- Get list of forms in each project and their total submissions
- Report total submissions per project and across projects
from pprint import pprint
import requests
from requests.exceptions import HTTPError
TOKEN = 'putyoursecrettokenhere'
BASEURL = 'serverURL/v1/'
headers = {
'Authorization': 'Bearer ' + TOKEN,
}
xheaders = {
'Authorization': 'Bearer ' + TOKEN,
'X-Extended-Metadata': 'true',
}
total_submission = 0
try:
r_projects = requests.get(BASEURL + 'projects', headers=headers)
json_projects = r_projects.json()
PROJECTS = len(json_projects)
print(f'\nTOTAL PROJECTS: {PROJECTS}')
for i in range(PROJECTS):
# print(f'{json_projects[i]}')
PROJECT = json_projects[i]
project_id = str(PROJECT['id'])
print(f"\nID = {project_id}")
print(f"NAME = {PROJECT['name']}")
print(f"Archived = {PROJECT['archived']}")
project_submissions = 0
try:
r_forms = requests.get(BASEURL + 'projects/' + project_id + '/forms', headers=xheaders)
json_forms = r_forms.json()
FORMS = len(json_forms)
print(f'TOTAL FORMS: {FORMS}')
for j in range(FORMS):
# print(f'{json_forms[j]}')
form = json_forms[j]
form_id = str(form['xmlFormId'])
SUBMISSIONS = form['submissions']
project_submissions = project_submissions + SUBMISSIONS
total_submission = total_submission + SUBMISSIONS
print(f" SUBMISSIONS: {form['submissions']} NAME: {form['name']} STATE: {form['state']} ")
except HTTPError as http_err:
print(f'HTTP error occurred: {http_err}')
finally:
print(f"PROJECT SUBMISSION: {project_submissions}")
except HTTPError as http_err:
print(f'HTTP error occurred: {http_err}')
except Exception as err:
print(f'Other error occurred: {err}')
finally:
print(f"TOTAL SUBMISSIONS: {total_submission}")
TOTAL SUBMISSIONS: 151220
Welcome to the ODK community!
A quick idea, apologies for brevity as I'm mobile.
Since you are using Python, would the pyodk package be useful for your purpose?
Alternatively, you could use the R package ruODK to access amd download submissions.
When you run the backup, maybe increasing server size might address the error you're getting?
Many Thanks
I will definitely look at pyODK. The main concern is having a restorable backup.
Meanwhile I am perusing writing a python script to download data and write to a file.
from pprint import pprint
import requests
TOKEN = 'TOKEN'
BASEURL = 'https://url.com/v1/backup'
headers = {
'Authorization': 'Bearer ' + TOKEN,
}
response = requests.get(BASEURL, headers=headers, stream=True)
print(response.headers)
Content_Disposition = response.headers.get('Content-Disposition')
responseContentType = response.headers.get('Content-Type')
x = Content_Disposition.split("=")
responseFileName = str(x[1])
responseFileName = responseFileName.replace('"', '')
responseFileName = responseFileName.replace(':', '')
print(responseContentType)
print(responseFileName)
if responseContentType == 'application/zip':
# 200 MB chunk size
with open(responseFileName, mode="wb") as file:
for chunk in response.iter_content(chunk_size=200 * 1024 * 1024):
file.write(chunk)
So far, I have downloaded 1.5GB data and script is still working.
I will get back with the status of downloaded file once completed
*** Update ***
Confirmed that the downloaded archive (5,10,21,41,782 bytes) was with errors (tested using 7zip)
Best Wishes
Vivek
Backup from the web UI is no longer available in latest version. As you have already taken a snapshot, I would recommend you upgrade to the latest Central version.
How do I backup the REDIS for Enketo
You'll need to dump the Enketo databases and secrets from your server by running the following commands:
docker exec central-enketo_redis_main-1 redis-cli -p 6379 save;
docker cp central-enketo_redis_main-1:/data/enketo-main.rdb ~/enketo-main.rdb;
docker exec central-enketo_redis_cache-1 redis-cli -p 6380 save;
docker cp central-enketo_redis_cache-1:/data/enketo-cache.rdb ~/enketo-cache.rdb;
docker cp central-service-1:/etc/secrets ~/;
1 Like
@Dr_Vivek_Gupta, I would not use the API backup for this because it does not include the data in the Redis DB which is very helpful for a complete restoration. I would...
-
Restore the VM snapshot to another machine and see if you can upgrade that machine without any problems. If you can do this, you've confirmed you can have a smooth upgrade which is ultimately what you need to.
-
If you want to be extra safe, dump the Postgres DB and the Redis DBs (as @KagundaJM suggested) from the old machine and store it somewhere safe.
# stop nginx and service to prevent new incoming data
docker stop central-nginx-1
docker stop central-service-1
# export secrets
docker cp service:/etc/secrets ~/;
# export redis dbs
docker exec -it central-enketo_redis_main-1 redis-cli -p 6379 save
docker cp central-enketo_redis_main-1:/data/enketo-main.rdb ~/enketo-main.rdb
docker exec -it central-enketo_redis_cache-1 redis-cli -p 6380 save
docker cp central-enketo_redis_cache-1:/data/enketo-cache.rdb ~/enketo-cache.rdb
# export postgres db
docker exec central-postgres14-1 pg_dump -Fc -U odk odk > ~/central.bin
# start nginx and service
docker start central-service-1
docker start central-nginx-1
3 Likes
Many Thanks Kagunda and Yankowa for the concise instructions. These are quite self explanatory. May you also consider adding these to the main backup documentation page.
I will be able to try them out on Monday as the server access is restricted.
Best Wishes
Vivek
Many thanks,
With your directions, I have managed to complete upgrade to latest greatest version of Central. The support that you have provided was absolutely invaluable
Best wishes
Vivek
2 Likes