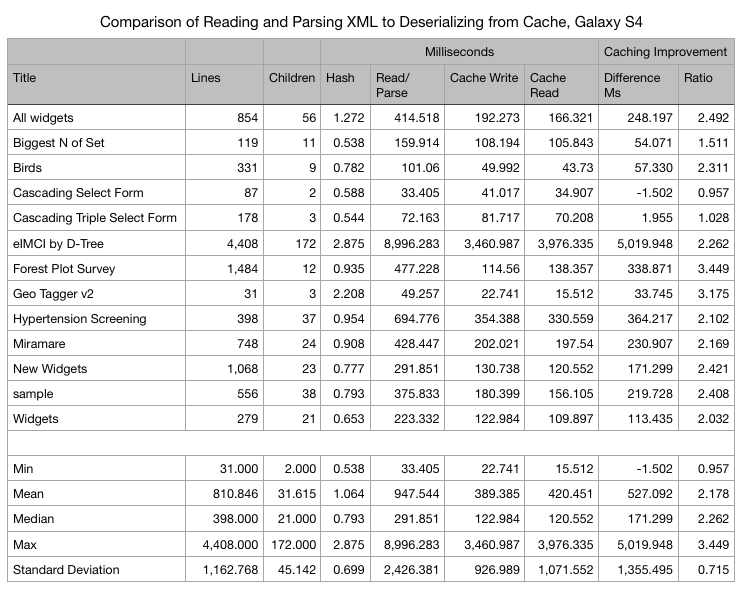
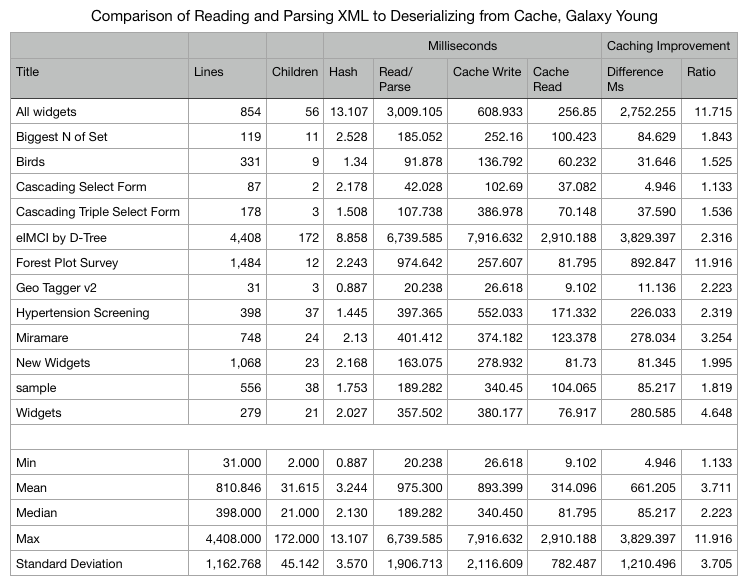
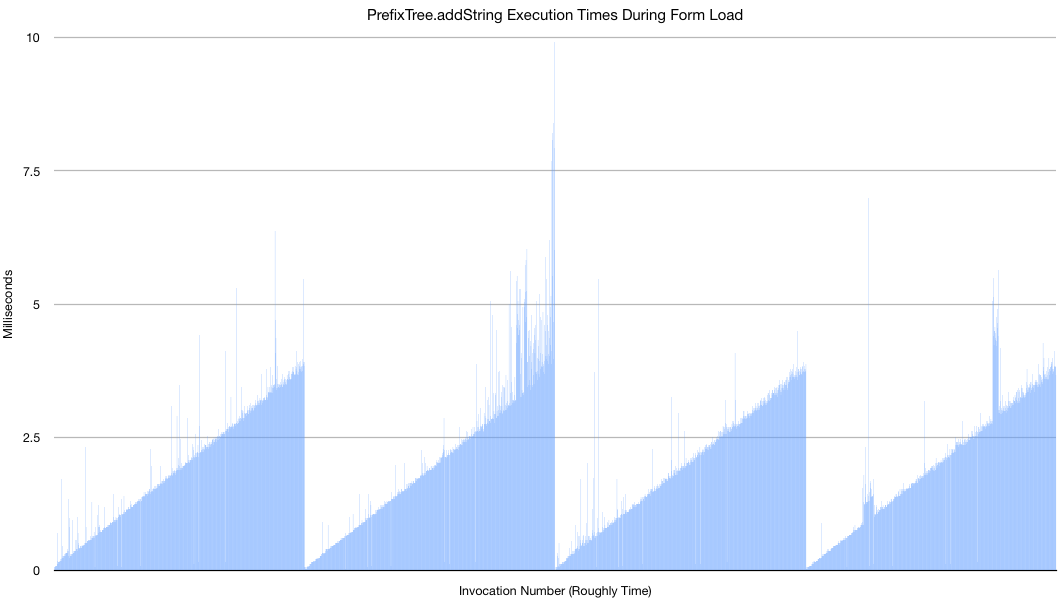
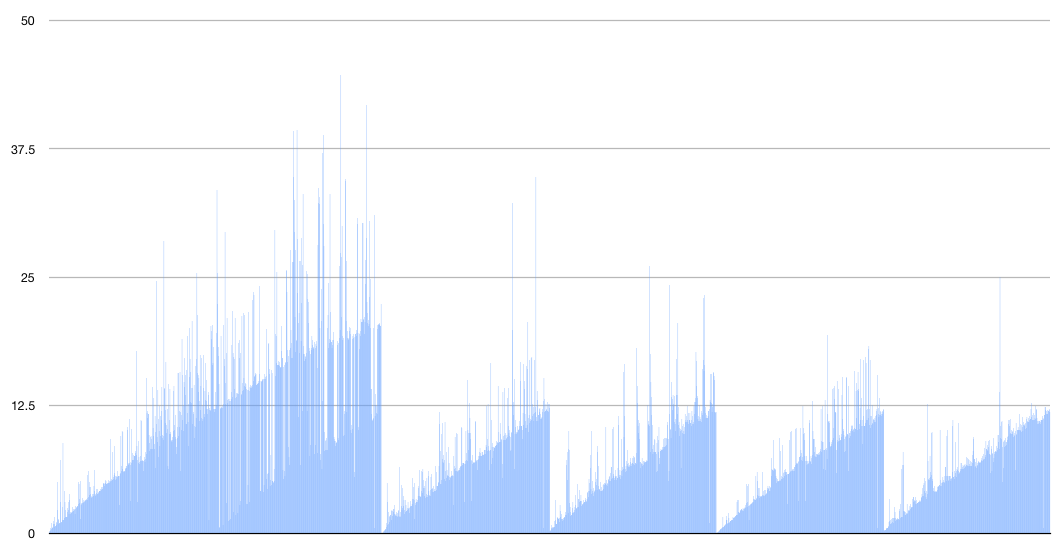
Some changes we’ve made recently in JavaRosa, and one (in a pull request awaiting merge) in Collect, improve performance of Collect’s large form handling. There are more improvements that we should pursue. Here are two.
Caching
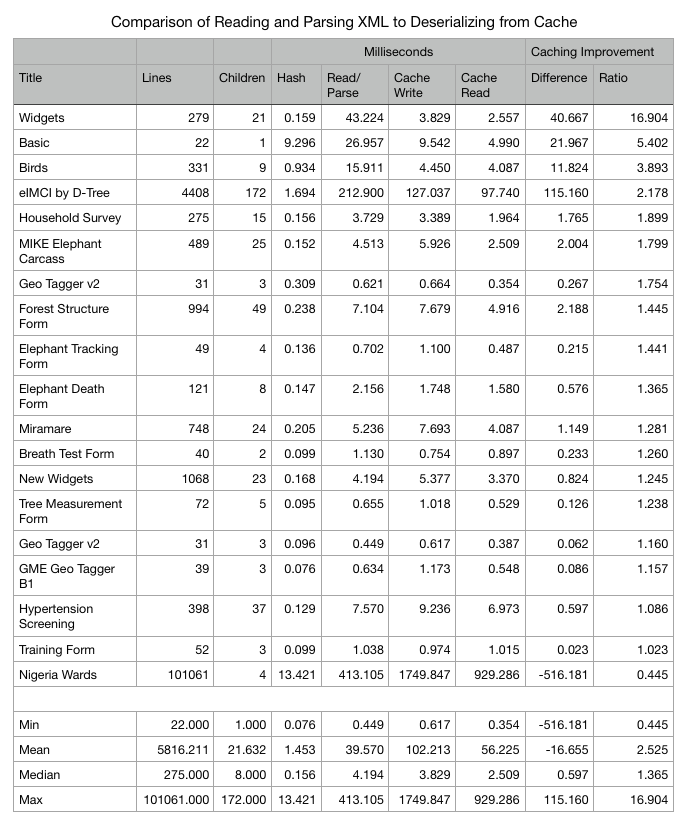
I modified FormLoaderTask to load the form from the cache if it exists, and always load it from the XML file, as if it didn’t exist in the cache. The results of my small set of experiments show faster times loading from the XML file.
12-03 23:21:51.478 Attempting to load Nigeria Wards Medium.xml from cached file: /storage/emulated/0/odk/.cache/09d2702d6aae1b2d440ee604f2b7485e.formdef.
12-03 23:21:56.005 Loaded in 4.526 seconds.
12-03 23:21:56.005 Attempting to load from: /storage/emulated/0/odk/forms/Nigeria Wards Medium.xml
12-03 23:21:59.083 Loaded in 3.076 seconds. Now saving to cache.
Saving to the Cache
This is the slowest of all:
12-03 23:23:17.885 ... Now saving to cache.
12-03 23:23:28.421 Saved in 10.535 seconds.
Solutions
It may be that we should eliminate form caching altogether. Perhaps we should add a General Setting to Collect to let users run either way, to see what we learn.
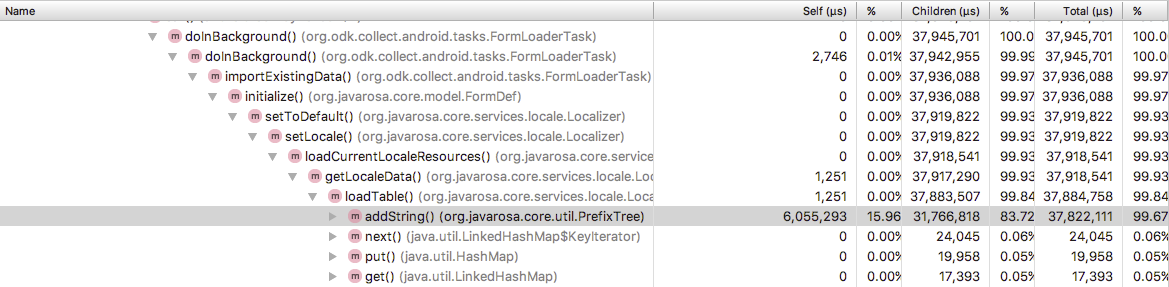
addString in org.javarosa.core.util.PrefixTree
As you can see from this Android Studio Android Profiler report, and this log excerpt (from a different, unprofiled, run), JavaRosa’s PrefixTree is inefficient. I had a quick look at this class a few weeks back, and felt we could make big improvements to its performance.
12-03 23:24:35.517 Initializing form
12-03 23:24:38.998 Form initialized in 3.480 seconds.
I’m inclined to start looking into the PrefixTree class, while others consider the idea of removing the form cache, or making it a user-selectable option.
Seeing what can be done to speed things up in PrefixTree sounds like a good idea.
I thought the whole point of the form caching was to speed up subsequent loads. Is that not what it's for? Or are there certain kinds of forms that it does speed up and others that it doesn't?
That seems like a good idea. The first place I'd start is seeing whether there's a difference between a form with a large primary instance and one that's big because it has one or more large secondary instances (like the Nigeria ward form). I haven't deeply looked at that serialization code but I also wonder whether it might speed up things like loading calculations or other specific features like that (rather than just targeting large instances).
My guess is caching was added as bandaid for slow form processing and now that form processing improvements have shipped, those improvements are dwarfing caching.
Really interesting how differently different kinds of forms perform! I think there's a pretty good range of forms there so I don't see an immediate need to time more.
The most immediate follow-up question I have is what the time difference is for the eIMCI form on a real, underpowered device like a Samsung Galaxy Young.
Do you have any sense of what determines whether a form will benefit from caching? Looks like secondary instances really don't work.
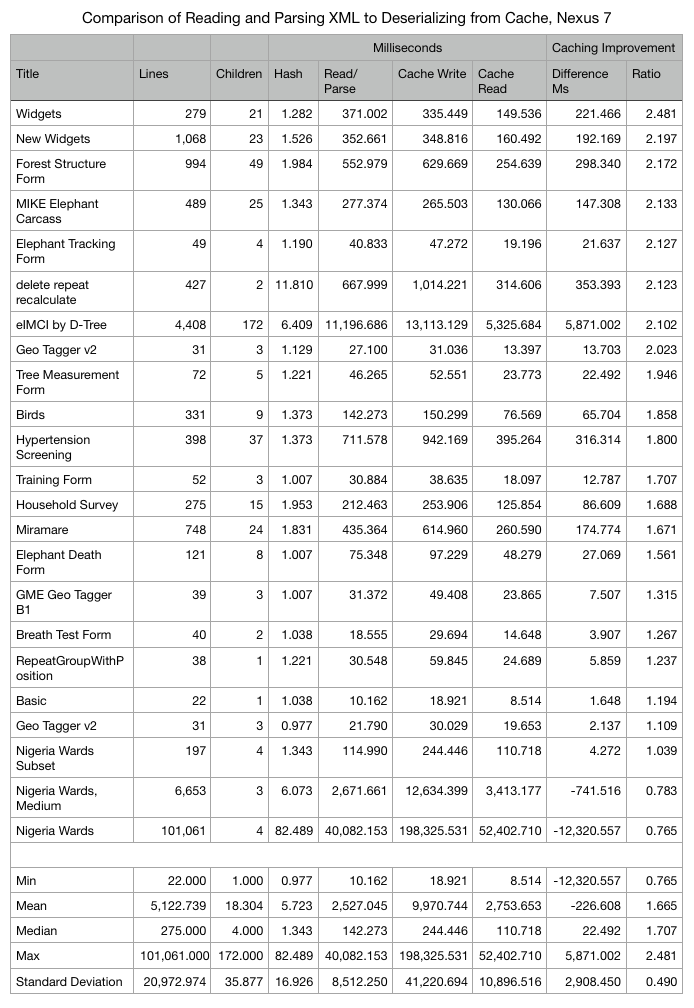
Yaw brings up a good question in Slack: What is the performance on an actual Android device? (I ran this on a fast MacBook Pro with a solid state drive.) I think I’d better build something to produce this data for all the forms on an Android device before doing much more analysis.
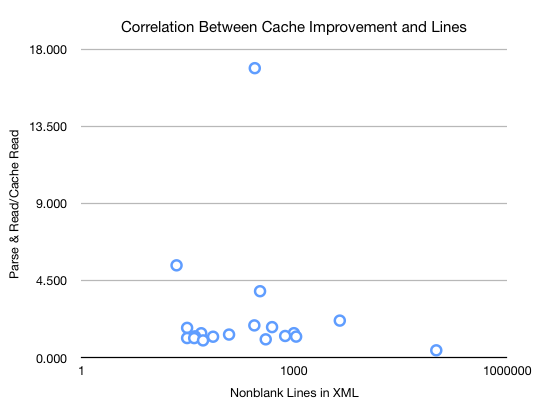
I added nonblank lines in the XML form, and as you can see, there’s no correlation between that and the performance improvement from caching.
Any ideas (even rough) on what makes a form be helped by this caching strategy? Off the top of my head I would say it looks like if the primary instance is long it helps.
For those interested in helping with this investigation, the tool runs timing tests on all forms present on the device. It logs times in ms -- the output is the first 6 columns in the screenshot above. I used adb logcat -s "TimeParseAndCache:I" to see just the log output from that class.
I tried this with a Galaxy Tab A and got very similar results. I would be interested in seeing how much longer eIMCI takes on an underpowered phone. @mmarciniak90@kkrawczyk123@Grzesiek2010 any chance one of you could try this?
Clearly it makes no difference for small forms. A 6 second difference for eIMCI worries me, though. I tried this with a large confidential form with 1877 lines and 147 children and got a 2 second difference: 1877 | 147 | 2.411 | 3109.070 | 1264.679 | 1142.609
New hypothesis that should be verifiable just by looking carefully at what is cached (the DAG): forms with a lot of dependent fields (calculates, relevants, etc that use other nodes) see a big speed up when cached. @michal_dudzinski this is starting to overlap with what you’re working on so maybe you have ideas.
I added some timing logging to that function, and graphed the results from loading a much shortened version of the Nigeria Wards form. This looks to me like O(n) time. I think we can improve the algorithm, but perhaps we can stop using PrefixTree altogether. It saves RAM by condensing many strings into a tree structure, where common parts are shared.
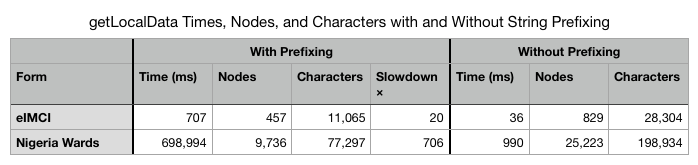
The getLocalData method, which creates and loads the PrefixTree, takes 20 times as long when the packing is enabled for eIMCI, and 706 times as long for Nigeria Wards.
Not packing the strings requires more space. According to the Android Studio Profiler, the “shallow size” of a PrefixTreeNode is about 32 bytes. Add in a List of references to children, and the character array size, and you have the size of the node. A rough estimate for the not-packed Nigeria Wards PrefixTree, with its root node, and all descendants being immediate children, is 2 MB.
Can we afford the RAM, and turn off the string packing?