1. What is the issue? Please be detailed.
Hi,
I'm wondering if someone could help advise on what is the best way to connect the form submissions data in ODK Central (hosted in Digital Oceans, or Google Cloud Compute) to BigQuery? Thank you very much in advance for the help.
What have you tried so far?
Hi,
Haven't tried anything, still in planning/brainstorming stage. Have been reading through the documentation, forum, online material, and thought of some ideas. For example, using ODK odata API (doesn't seem to be supported by BQ without third-party connectors), the general ODK REST API (maybe, but not so clear how to ingest it into BQ), using Cloud SQL (not sure if ODK central can support this, i.e., external postgres, perhaps this could be a solution?). I see that there is a connector for Data Studio, but not for BQ, and for the Data Studio, it's only for limited use cases. The other thing I was looking into is the offsite ODK backup to Google Drive (but it seems that it might make it more complex and not so efficient/direct). Data Studio can connect to external postgres (this might work, assuming the configs and traffic permissions can be set through the VM and Docker instance that host ODK central), but I don't think BQ can, unfortunately.
I'm hoping you or someone may already have some experience with connecting ODK Central to BigQuery. Would appreciate any pointer. Btw, I found some info on the older ODK Aggregate (on AppEngine) setup with BQ, but not for ODK Central.
Thanks
A year ago, I couldn't find anything straightforward or generic, so I ended up coding the integration myself. I am using Firestore as an intermediary and the integration with BQ is based on one of their extensions. I guess the Firestore part could probably be skipped, but roughly and simplified, what I am doing, is to poll the central audit log api on scheduled basis and then react to the events as follows:
- project create/update -> ensure a dataset for this project exists in BQ
- form create/update -> ensure a changelog table for this form exists in the project's dataset. These tables are very simple and represent something like raw, append only log for the submission data with just few columns: submissionId, eventDateTime, submissionData (text column, containing the JSON representation of the submission data)
- submission create/update -> Get the submission record as JSON from the Central's OData API with expand=* and then insert this json together with the submission id and the event time in the form's changelog table. (As a side note I am currently struggling a bit with submission.update.version which fires when a submission is edited in Enketo)
Consuming the data:
- For every changlog table there is a view in BQ, to get the current state for each submission (the json payload, per submissionId as of the latest eventDateTime). Let's call this changelog_latest.
- form.publish event -> I get the form xml for the latest version, extract the schema(fields, field paths, repeats), and will then programatically create a view in BQ, that will query the changelog_latest. In order to extract the data from the submission JSON, this view will extensively abuse JSON_EXTRACT_SCALAR and some custom UDFs to deal with data type conversions, repeats and what not.
So the end result is a single view per form (with array of records columns for the repeats) as per the latest form schema.
2 Likes
Hi punkch,
Thank you for sharing the info. I was hoping there may be a simpler answer or an available functionality in ODK :), but it sounds like you have done a deeper investigation and this functionality is not supported, at least not as of last year, unfortunately. Probably still in similar state right now.
The solution that you mentioned sounds quite complex and require various services such as the Firestore, task orchestrator/scheduler to do the various checks, listen to the triggers, call the APIs (perhaps using Airflow or Cloud Functions?). And will have to ensure reliable and scalable upsert operations that can handle errors/partials/interrupts, avoid duplicates, etc. and maintaining the connector over time as ODK/BQ evolves.
At least for my use case, not using any triggers, and simply run a periodic (cron-type) jobs to sync the ODK data with BQ would be sufficient, however even this is non trivial to make it robust, scalable, and maintain over time.
It sounds like you were having some issues, and didn't get to fully deploy it for operation? Or were you able to deploy and have it operational?
Thanks again for sharing the helpful info!
You can use an external database with Central, but we don't recommend accessing the database directly: the database is not considered user-facing, so its structure may change at any time. I haven't worked with BigQuery, and I'm not sure whether Cloud SQL is the right approach, but you could consider looking into this approach to populating a Postgres database using the Central API:
Maybe Cloud SQL could pull from such a database once it's set up?
I also wanted to link to Getting Data Out in case that discussion is useful.
Hi Matthew,
Thanks so much for the helpful reply. Yeah I've been thinking about using the cloud sql as an external postgres that central runs on. It seems possible based on the odk-central documentation, however the doc mentions that "... Using a custom database server, especially one that is not local to your local network, may result in poor performance. We strongly recommend using the Postgres v9.6 server that is bundled with Central. ..." I'm wondering if you can share your thoughts on this in the context of using cloud SQL as the DB.
Mathieu Bossaert's SQL functions that use curl and central OData API to pull the data out looks cool. Are you saying that while the odk-central postgres DB schema may change over time, the OData API (and thus Mathieu's SQL functions package) should be more stable? One drawback of using this will be that you'll end up with two "redundant" copies of the postgres db. Might be okay, but may not be as efficient in terms of resource use.
Another thing I'm wondering is how do you handle the odk-central postgres forward-compatibility when ODK Central is updated over time. E.g., do you extract all of the data, and create a brand-new (potentially different schema) and re-populate the forms & submissions data back in, or do you maintain the schema stable, and when you said that the structure may change at any time, it will at least maintain backward-compatibility of the schema, and might build on top of the existing over time? Or perhaps ODK Central is partitioned into two independent parts (the server SW and the DB), and updates only apply to the SW part (but I guess they are bundled together in docker-compose?).
Thanks
Exactly. The API is the official way to communicate with Central, and we take care to avoid breaking changes where possible. On the other hand, any integration that relies on the database schema will be fragile. (By the way, the schema of the Central database is very different from Aggregate. For example, at the time of writing, there is a single submissions table for all forms, where submissions are stored as XML.) So I think whatever approach you end up taking should use the API in some way.
I don't quite understand this question, but I'm hoping that what I wrote above helps clarify this too. One thing to keep in mind is that Central has a form versioning system, and submissions can also be edited. (Might not be relevant depending on your workflow.)
Oh I see, so the base postgres contains XML values for the submissions, and the API is in a way the parser that transforms it into a stable and standardized format. And when you say that the schema changes, perhaps you're referring more to the XML structures rather than the postgres database/table schema. If this is true, I see what you're saying that perhaps Mathieu Bossaert's solution could be the way to go, since you need to parse the XML anyway at some stage in the pipeline.
My second question was about how the existing data is handled when a new odk-central version is released (if the schema can change frequently). If the above is correct, then perhaps what will happen is the base postgres (db, tables) schema is stable, and what might change for new releases is the XML structures (at the row-level). So existing data will just remain in the db (containing the old XML format), and new form data will use new XML structure, and perhaps the API is backward-compatible and can detect the XML version and parse it accordingly.
When a new version of ODK Central is released, it will usually include database migrations that change the structure of the database (adding tables, adding columns, moving columns, etc.). However, the API will continue to return the same values (with the exception of changes noted in the API changelog). A database migration will also never modify the raw data (the XML). In other words (to summarize), the database that Central uses is for internal use and will change in small and large ways with each release, but those changes won't be visible over the API; and it is the API that is the only stable/official way to communicate with Central.
1 Like
Got it, it's clear and helpful. Thanks a lot @Matthew_White! Appreciate the help.
It is deployed and operational and indeed complex. I use the Firestore as interim to orchestrate the cron jobs (it is only one actually that polls the audit log) and then, depending on the received events, I replicate the data of interest to firestore documents and transform as needed. Changes to these documents would trigger firestore trigger functions and interact with BQ. The interactions with BQ go through something like a task queue (another firestore collection), which handles retries on interruptions and etc. Mainly caused by the rate limits of the BQ apis.
You may try to get the deltas of the submissions per form via the OData API on a scheduled basis, and putting filters for createdDate and updatedDate to only get what happened since the last cron run.
What I wanted to warn you about, is to not expect a smooth ride. Regardless how you get the data, you'll need to transform it. It is not just the schema, but things like, i.e. BQ has some nice GEO functions, but their geo type unfortunately doesn't support altitude, so is needed to strip it from the coordinates in the odata geojson fields.
If of any interest, here is an infrastructure diagram. Works great with a managed Google CloudSQL database. No problems so far, even though the Postgres version is 12.8.
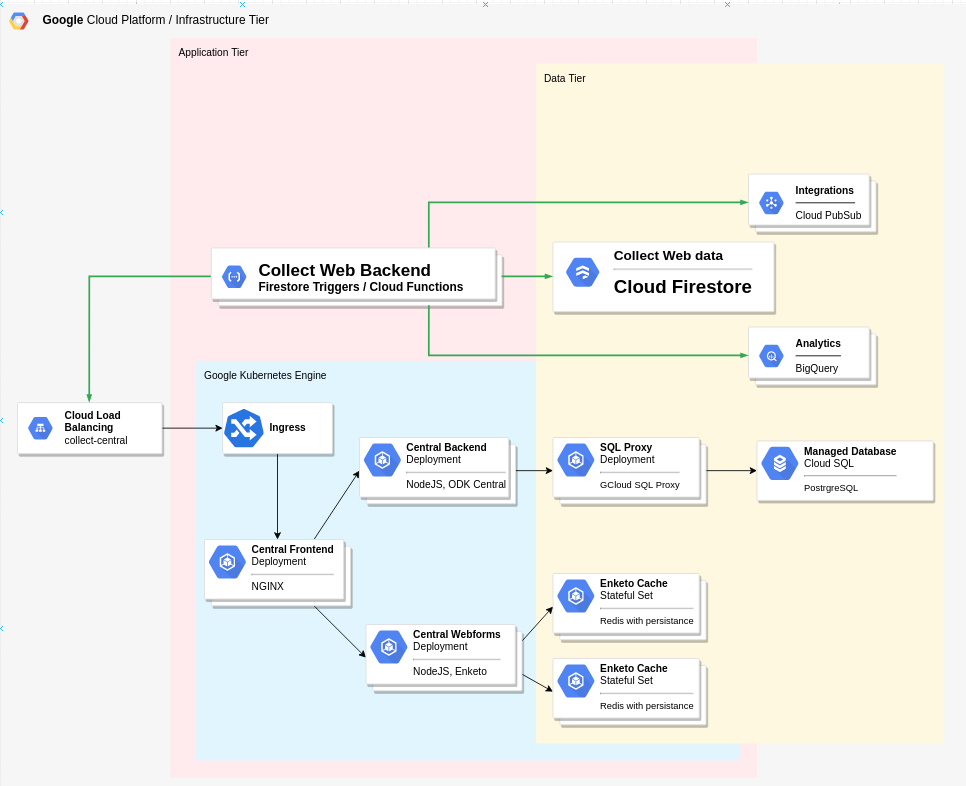
1 Like
Hi @punkch
Oh nice, I see, looks like a quite significant deployment (and lots of $$) ![]()
I was hoping for a much simpler solution, something analogous to the OData connection to PowerBI or Excel that are already supported, but for BQ, but I see now that this is not available, and some development utilizing the central API is likely needed. Btw, are you using Firestore for other functionality, if not it looks like another potential solution is Mathieu Bossaert's SQL functions, which is based on central API. I was thinking about direct integration with the odk-central postgres (which could simplify the process), but per the discussion above with @Matthew_White, it seems not recommended as it may not be as stable.
Not sure if you are able to share this (if you cannot, I totally understand), but if you can, I'm wondering if you can share how much traffic or capacity (order-of-magnitude) is your system above handling? I've been under the impression that even a small single VM can handle reasonably significant scale (especially without large media attachments).
Thanks for sharing the informative and interesting info @punkch!
Yes, this is true. Our peak usage was 10,000 submissions (no attachments though) within couple of hours (like 200 data collectors sending their daily work when online in the evening) and central handled this without problem with just 1 cpu allocated. The managed CloudSQL instance is with 2 vCPU and 4GB RAM, but the CPU utilization is constantly around 5% while the memory used is around 1 GB.
Ah got it, awesome. Thanks!!