The XLSForm template is the authoritative, maintained reference around differences between ODK Collect and Enketo. It replaces the XLSForm website reference table which was not very consistently maintained. The only missing item from the XLSForm template that I'm aware of is table-list as we discussed in XLSForm Template - Few missing Appearances. The template is linked to from https://xlsform.org/en/ref-table/ and https://docs.getodk.org/xlsform/
The first document you link to is the best high-level summary of the major differences that I'm aware of. We use the first section as our "north star" when thinking about alignment work. If there are items you think are missing, please highlight them in this thread. We try to keep this list to big themes.
The two major items in the differences list are bugs around nested repeats and read-only being static. The source of these issues run deep in the engine implementation and are connected to other concerns like performance. We have been actively working to identify a way forward to addressing them holistically rather than making piecemeal patches as we had previously been making. We're not entirely sure what the approach will be yet but will be talking more about it in the new year. We are also looking at strategies to further align the user experience.
Thanks!
I would appreciate one priority on dynamic read_only, please. And to integrate read_only and guidance_hint into the template, as columns.
Where do we document smaller differences between Collect and Enketo, for possible adaptions, e.g.:
- number widget (slider buttons)
- acknowledge type text
- guidance_hint UI icon ?
Kind regards and thanks to you all for the great progress with template, guideline, Enketo adaptions, entities, etc.
We currently have both listed in the "additional columns" sheet. We really debated what to do with less-common columns. We currently think it keeps things tighter to push some out to "additional columns" but are open to feedback. We won't make immediate changes but if we hear more suggestions about columns to include we'll do a new version.
Can you please elaborate on what this means?
I've put them in the doc in the "to triage" section for now.
We use it - together with a choice_filter - to auto-set the only valid answer for this case (Household member), but allow manual selection for the other cases (HH members).
Here is an extract of a complex study (refugees context).
Line 30. The head of HH must be the first member in the HH roster. We used a choice_filter reducing the relationship choice to "Head" and set it to read_only. Then, we can use the same structure for the following HH members, with manual data entry for the (other) relationships,
Line 32. Analog, for a question on child vulnerability, i.e. orphan-ship, living without (biolog.) parents. If the HH member is declared as "Son/daughter" of a female Head of HH, the mother (she) is living in this HH. We use a choice_filter and set the only answer to read_only.
HeadHousehold01.xlsx (25.1 KB)
This is an extract, the real form does the same for the father, and a lot more consistency checks, e.g. based on birth dates and age differences.
The extract also shows our language mixture of EN and AR (RTL alignment). The questions/warnings communicated to the interviewee are in AR, the rest is in EN for the (bilingual) enumerators. We copied the EN texts, e.g. for hints etc. in the AR cells, by Excel formula.
read_only (even static) is an option to use typed variables, like select, which can be auto-set, with the normal advantages of having labels, incl. export (and SPSS labels).
We use this e.g. to aggregate ages to age groups, see an example: AgeGroup01.xlsx (11.1 KB). To show the group, also stresses awareness of the enumerator to get the correct age info at group borders.
This "typing" is not possible with calculate (or "hidden") type. In the ODK future an appearance option to hide variables could be another and sometimes preferable option, see discussion in Github. But there is already a workaround: to use a typed variable without a label (and hint) with calculation, see https://xlsform.org/en/#calculation.
guidance_hint. We use it as additional "help" to the enumerator, during training and to show filters (relevant conditions) in form print-outs, and (form overview during training). We created a full paper back-up of the empty form for remote field work, e.g. for device/battery/app breakdown.
acknowledge type text
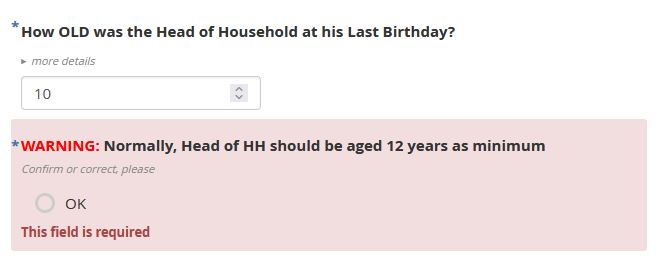
We use acknowledge type often for warnings ("soft control"), together with relevant and required. The enumerator has to go back and correct or can confirm the warning (QA issue) and go on. Advantages against a note are: It demands confirmation, is documented ("OK") in the data and might be used for QA and data cleaning. (Even by supervisor monitoring in the field.)
Besides equal system text ("OK" only, without "Please continue"), see screenshots below, we would appreciate an option to configure the text, e.g. as appearance.
guidance_hint
We would appreciate: Similar Icon appearance for Collect and Enketo (instead of the repeating text line ""more details") and the option to configure the appearance also in Enketo.
number widget (slider buttons)
In Collect no up/down buttons, but in Enketo (with to narrow layout).
Also, the colour for **required *** is different (red Collect / blue Enketo).
Not sure in the value in adding other differences with Enketo given the upcoming webform replacement, and they're minor display differences, but adding here in case relevant.
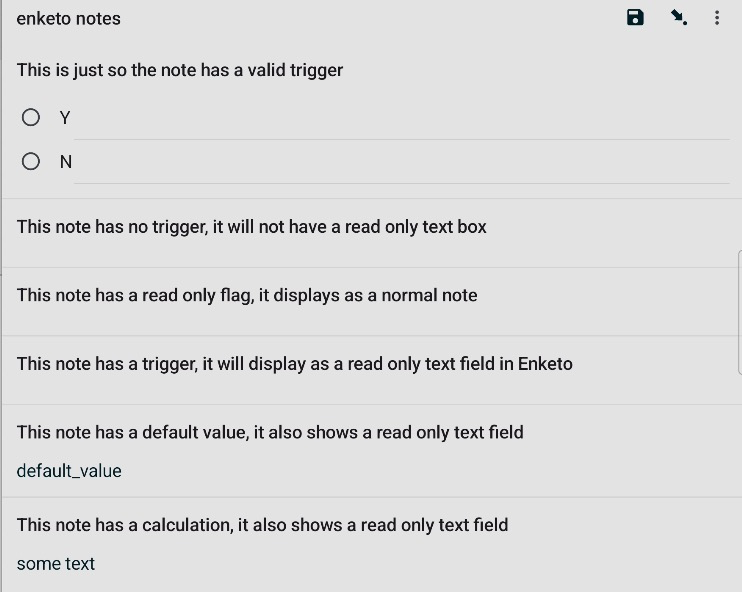
Field type note in Enketo displays unexpected textbox if there is a trigger, but Collect doesn't.
I already deleted it as it took no time to make. Just add a note field with a trigger to test it in any form, my screenshots show what I saw in Collect and Enketo.