(TL;WR: Is it possible to specify a relational schema in ODK Central or any other ODK product or ODK clones?)
Hi all! So I think my question has been asked too specifically in the past (for example), so I'd like to ask a very wide question.
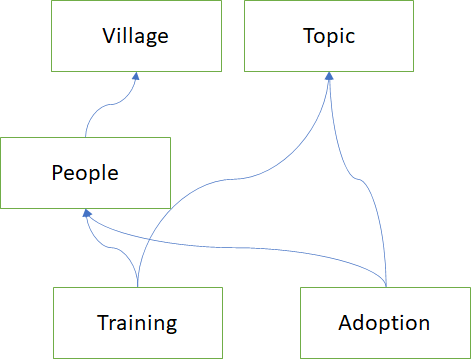
Let's say I am working with a government who is teaching farmers some new techniques and then in some time they will go and see if they have adopted them. I could create one big form to collect all the information and have columns be empty if the information doesn't fit (like have training empty if I'm looking for adoption), but that would result in many many rows with empty columns. So I might suggest a schema (or way of arranging information) with few tables and these fields:
Village: Village_Name
Person: Full_Name, Village
Training: Person, Topic, Date
Adoption: Person, Topic, Date, Applied_yes_no
Topic: Name
The schema might look like this, where each arrow shows that information is referenced from the table that it points to:
Now we can design an ODK Collect form to capture data from each form independently, with no blanks.
But if I wanted to reflect the fact that my People table is used in both Training and Adoption so that enumerators wouldn't have to capture name as a short-text, but as a drop-down list, what are the solutions for storing this information relationally?
Note 1: I'm not asking about how to organize the information in the XLSForm, that part is simple enough to do manually by copypasting for one collection. I'm asking if it's possible to set up the relationship at the storage side.
Note 2: Let's ignore the additional complication of "offline data not being available until sync" and other detailed issues.
Is there any ODK product to let me store this information as I have drawn? How do others solve this problem?
In brevity as I'm on mobile, there are some bells ringing:
The entity based data collection work group is discussing such longitudinal workflows, where data capture refers back to previously recorded entities. They co-ordinate on Slack and meet up separately. Their notes might be of interest.
My dirty solution for a register of previously recorded entities is to collate the data and update a Google Sheet, which in turn syncs to our data collection devices. Enumerators there can refer to the Google Sheet if they have questions about a case history.
@mathieubossaert has posted about his ODK Central to Postgres DB to DB pipeline. This might be a starting point for an export directly into a custom data model.
Lastly, there is the frictionless datapackage spec for datasets with arbitrary schemas.
Thanks Florian, really interesting stuff. I'm interested in this Slack group and their notes.
So in terms of your google sheet syncing into the data collection services, I think that's really interesting, you could make the google sheet the SOURCE of data that would get read into the survey instruments?
Sorry I don't know what frictionless datapackage spec is! :-\ Looking forward to see if Mathieu Bosseart has some more feedback!
https://frictionlessdata.io/ really worth a read! I keep wishing they'd extend their data spec with a form spec and become the JSON equivalent to XForms and XLSForm.
My Google Sheet is synced on the data collection devices, but unrelated to ODK Collect. It's just a reference of case histories to inform the field team leaders when they proofread and QA submissions before upload.
I am not sure to understand what you want to achieve... Please tell me if I misunderstood.
We store our data, even those collected through ODK in a relational data base.
And we generate our choices lists with SQL queries. Choices are stored into choices sheet or into csv media files.
This allow us to personalize drop down list by filtering rows with previously selected answers.
You should then sync csv files on the phones with sync tools, or publish new form versions on ODK severs.
Please provide more information about the high-level problems you're trying to solve. Is your workflow highly dynamic (e.g. villages are constantly added and removed)? Is there a strong need for information about past encounters in the field (e.g. you need to know exactly what happened in Person X's training when assessing their level of adoption)? Are you dealing with 100k+ people that you need to split between your data collection teams? Are you trying to address some kind of reporting problem?
ODK tools don't currently provide explicit support for highly-dynamic workflows or workflows that rely on historical data. As @Florian_May mentions, this is an area we'll likely provide some targeted tools for. Note that connectivity is often the limiting factor and that there would still need to be a thoughtful workflow design.
From what you describe, a typical setup would be:
first build up the village and topic lists as internal or external datasets.
use a form definition to build up a roster of people, generally at their first training. Build selects from the village list and topic list to create the person-village association and the person-topic-date association.
either periodically or once the first round of training is complete, download the data from the enrollment or training form. Clean the data as needed and produce a "people" dataset with the columns you need.
attach the people dataset to the training and adoption forms. You can build a searchable select from that, for example.
use the ids from each link question (e.g. villageid, personid) to merge the various datasets for analysis.
This is interesting to me, is the process automated? Gneerating Choices lists w/ SQL queries, that's cool! I think we did something similar... but I didn't think to sync csv files on the phone, I don't know how to do that.
Yes! Exactly this! I mean, its not important to know during the field data collection, but during the analysis phase, It's important to be able to store the raw data so that I can eventually find out "it's the female 16-20 potato farmers without market access that applied this technique the most". This insight is what changes interventions, but can not be rescued using the aggregate data like (234 people were trained of which 130 were female... bla bla).
Lets go back to my first example: we want to teach a farmer once and then months later go back to see if they executed that training. In my experience, left to their own devices, the ODK-survey architects will construct two forms, with one field in each that marks the person.
If the architect could use the "national ID number", then that would be perfect to match them, but many projects work w/ people without IDs, or in situations where gathering that info could be dangerous.
"DOB" can be uncertain sometimes, "Phone number" can be shared amongst many people, "address" isn't relevant in some places... etc etc. It's a big problem!
The architect could use biometric/QR code etc... but let's keep things simple
Since the architect doesn't have a good identifier, they will use "full name" as short-text in each. When we would get this data and try to match up the short texts, we have to use advanced string-matching algorithms to connect the data.
I solved this problem by connecting relational dbs to ODK forms, but it is a pretty high-tech solution (which I'd be happy to talk about btw), but I guess that's my question is: How is this not a pretty big requirement by the ODK community?
If I'm understanding correctly, you have addressed your own needs, @Amit_Kohli, is that right?
When building a list of participants to choose from, a common technique is to include multiple pieces of identifying information in the label. For example "First Name Last Name - phone number - dob". That way, any of these can be used to match or verify identity.
Distributing pre-printed participant cards with QR codes is also a common strategy and doesn't necessarily have to be complex if the codes just have random values that can be pre-printed. Those random values are then assigned to a specific participant at the first training and used in subsequent ones. Form design can provide a path for handling loss of id card.
I understand that it would be helpful to have more guidance and support around these workflows and that's something we're working on. These are hard problems to solve generically and we will hopefully have more to share soon.
Hi @LN . Yes I solved them for the company I worked for. But at a fairly massive expense, I worked on the solution on and off for about two years.
Now I'm a freelance consultant, and just wanted to check in to see if there had been any progress on this front. I believe storing data relationally would be really cool.
To the degree that you're working on a solution now, please let me know if I can help in any way,or if you would like me to show you the solution we developed, which lets any database table be converted to an xlsForm, it will automatically inherit the parent data, resolve the inner hirearchichal relationships and a bunch of other features.