1. What is the problem? Be very detailed.
Hello I can not access ODK Aggregate and ODK Collect since this morning. The problem is apparently linked to the server. It displays an HTTP Status 500.
One part of the script I obtain when I'm trying to access the server after entering my username and password is displayed below :
"État HTTP 500 – Internal Server Error
Type Rapport d''exception
message persistence layer problem; nested exception is org.opendatakit.common.persistence.exception.ODKDatastoreException: org.springframework.jdbc.CannotGetJdbcConnectionException: Could not get JDBC Connection; nested exception is org.postgresql.util.PSQLException: Connection to 127.0.0.1:5432 refused. Check that the hostname and port are correct and that the postmaster is accepting TCP/IP connections.
description Le serveur a rencontré une erreur interne qui l''a empêché de satisfaire la requête."
2. What app or server are you using and on what device and operating system? Include version numbers.
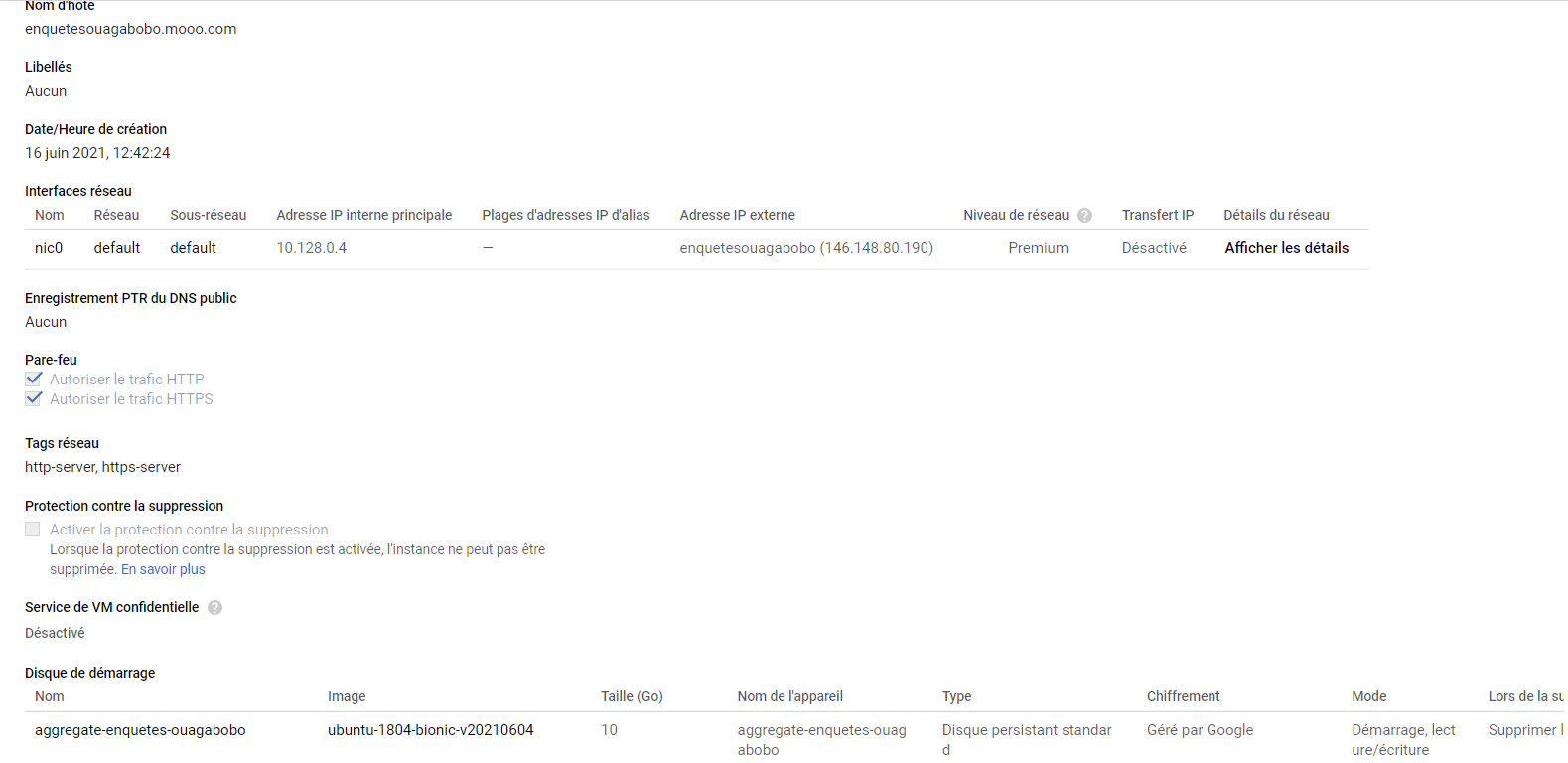
I'm using ODK Aggregate and Collect via a Google Cloud Platform launched in June. I didn't experience any problem until today. Logins and internet connection are good, GCP VM instance and billing are ok.
3. What you have you tried to fix the problem?
Changed the internet connection and browser, tried to access locally on my computer : no improvement.
Checked my GCP VM instance menu and parameters. I didn't identify any improvement or reason to explain the problem. The port script of the last days are not understandable for me...
Checked that the url is still operational on the website where I created it (on freedns.afraid). It's the case but when I execute a trace on the url it gives me a script I have attached. Tracing to enquetesouagabobo.pdf (74.7 KB)
4. What steps can we take to reproduce the problem?
I don't know. 5. Anything else we should know or have? If you have a test form or screenshots or logs, attach below.
My main GCP VM instances parameters are attached. I'm of course available to provide you any further information/details that might better understand and resolve my problem. I'm currently working with this server and I have to fix the problem very quickly !
Thank you in advance for your help.
After analyzing the GCP port script of my VM instance, I think it's linked to the disk storage that was full, rather than ODK itself. I have doubled the disk capacity, however it doesn't change anything in the scripts. I don't know what else to do as I don't master the command lines
I have attached the exhaustive port script of the last days (problem appears from page 10).
Do you think I can try to create a new VM instance with the same external IP address and a disk snapshot to keep my data ? By restarting from scracth, I will lost the data from Friday be obliged to reconfigure all the server and phones...
Thank you in advance if you have any ideas to help me.
Hi @Naej, I'm sorry to hear you are having these issues. Please note that Aggregate is no longer being supported. Central is now the ODK server. The post below has for more details about the end-of-life for Aggregate.
However, someone on the forum may still be able to help you.
In truth, I think the problem comes from a disk memory issue on GCP. I tried to reboot as it was explained there : 502 Bad Gateway nginx/1.14.0 (Ubuntu) while using ODK aggregate - #2 by yanokwa
But it's not working. The command line displays me : "Failed to write reboot parameter file: No such file or directory" It's the same with other similar commands like "sudo reboot -f". In my VM instance, there are serial port problems dealing with snapd.service or Snap Daemon that I don't understand and cannot fix.
If someone has an experience of GCP VM instance and/or a means to keep the same URL and host server with a new instance that would be great !
In AWS, I make a clone of the instance and then play around with it, for all the 'hit-and-trial' things. Not sure about GCP.
Moving the URL and associated backend IP is not that difficult. But you need to setup another machine with same config. Pick up the ROOT.war file of the existing server, and try to reuse that. Same for database.
The data might be left behind. Can you pull data via Briefcase? Try it. If so, do a pull and push to the new server.
However, its a long process. Make a clone of the existing server and see if it gets fixed, because thats your best line of work.
I have saved a system image and a persistent disk snapshot of my VM instance. I cannot pull data from Briefcase, the server is completely inoperative (whatever via Collect, Aggregate or Briefcase). I have recovered all the forms directly on the phones and will try to deal with it later.
"Pick up the ROOT.war file of the existing server, and try to reuse that. Same for database." : Can you explain how I can do that ?
The step is basically trying to replicate the same system config that you have on the old server. However, if you have the data saved, then better to setup a new server with bigger disk space.