In the recent OVH datacentre fire in Strasbourg, my group lost some of our REDCAP databases. Recovering the data set was easy from backup but we lost audit logs because these were not included in the regular data downloads. ODK seems to have similar vulnerability, but additionally lacks project level audit logs.
The server log includes information on user actions that may be required components of the data set (for instance for quality management and audit in clinical trials). At present ODK Central keeps a server log at the top (server) level and there is no function allowing end users and project managers to export entries for one specific project. Nor is there any function for sitewide admin to export complete log.
New feature adds an option to download a copy of the project specific entries from the server log
Also adds server logins to the audit log file, showing who has accessed ODK Central
Also adds function to allow sitewide admin to download complete server log.
In a future version of Central where form editing becomes possible, logging all edits to project variables in a project specific log file adds a fully auditable change history to the project data.
2. What are some example use cases for this feature?
I am downloading my project data from Central for backup purposes. I want to keep records of who has made changes to forms, ODK Central settings and user lists on this project. By including this log in the downloaded data, backups are made easier. By making this log project specific, different users can't see each other's logs.
My project quality manager detects unauthorised access to the system and uses the project log to identify the user credentials that were hijacked and then used to connect to the project.
A study staff member gets a new job. They are removed from the system. The project log provides evidence that their access to the project was revoked on date xxxx-xx-xx. This becomes part of the required data for a clinical trial.
With editing happening, all changes are logged to a project level encrypted project audit log (not visible to site-wide admin). This forms part of the required data for a clinical trial.
3. What can you contribute to making this feature a reality?
Really sorry to hear that you lost data and glad the loss was narrowly scoped.
I strongly advise against using exports as a form of backup. I'd recommend full-machine, offsite backups for any server that is handling critical data. Full-machine backups are guaranteed to be complete and likely faster to restore than selective backups. As a second option, the Central-specific backup does include all data that Central is aware of including all audit log entries. As of v1.1, it's possible to trigger a backup through the API meaning this can be scripted.
This is critical to you because you use projects as a form of multi-tenancy, is that correct? That is, each project is managed autonomously by groups that essentially represent different organizations? I think this has emerged as a relatively common usage pattern. I see @aurdipas likes this post and I believe he has a similar organization.
This is in contrast to another usage pattern which we see as even more common: an organization or group with a single Central server where projects represent specific efforts over theme, time or space. We are aware of this contrast and considering ways to support and harmonize those two organizational patterns. I do hear you that logs filtered by project could have value either way.
Adding this on a system level is something we are looking to do in the near-term. It's not clear yet whether this would be part of the existing system log or a separate access log.
In Central v1.2, likely out within the next month, edits will be possible and edit counts will be available in exports. In an upcoming release, a summary of changes will be added:
There is currently no plan to include this change history in any data or log export. We have heard requests to add it in the data export but it does represent a bigger effort. I completely understand that this kind of reporting is essential in a clinical trial context. As we've discussed, that is a fairly specialized use with many very complex specialist tools build for purpose. It would be good to hear from users not in a clinical trial context about how they would use this and how important it is to them.
A corporation operates in a biodiversity asset's home range, which potentially endangers the asset. Think turtle nesting beaches being impacted by infrastructure developments.
A regulator monitors the biodiversity asset using ODK, and sends the QA'd data to modellers.
The modellers use the data and the underlying assumptions, caveats, limitations, study methodology to infer knowledge on the population health of the biodiversity asset.
Should the modellers find that certain metrics of the biodiversity asset decline over a defined threshold, all regulatory hell breaks loose, meaning the corporation has to pay extra offsets and faces potential restrictions to their operations.
This means that lots of money rides on the veracity of the analysis and the trustworthiness of the data.
Since observational data captured by human enumerators consists of their claims to have encountered and measured specific things, we don't have truth, only claims. QA operators overlay the initial claim (the unedited, raw Submission) with their opinion (Submission edits) based on their expert knowledge.
This means that the audit trail of submission edits is a critical piece of information which could be subject to hostile inquiry.
If submission editing comes to ODK Central (in addition to editing the exported submissions in a downstream data warehouse, where these edits are logged), every pathway to access and analyze the submission edit trail would assist in making edits done inside ODK Central transparent and defensible.
How we would use the ODK Central submission edit logs:
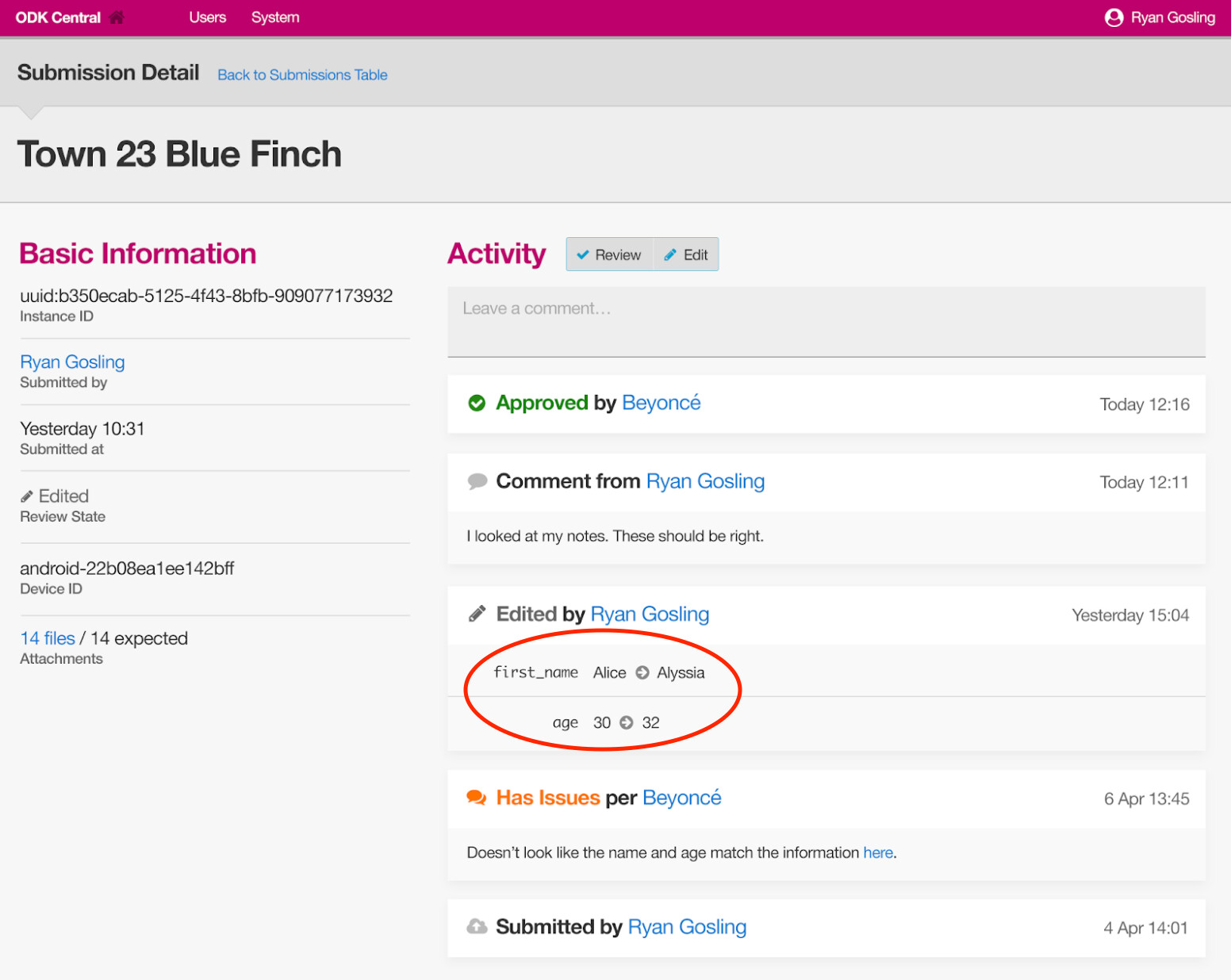
On a per record basis: Filter Submissions to "edited", inspect each by hand, as seen in above screenshot. This can answer questions for an individual record, but might not scale terribly well.
On a per form or project or server basis: Get a very generic table of form ID, submission ID, submission version (one for the original submission, one per edit), submission content (the entire submission after that edit), editor, datetime, (edit comments?). Answer some questions in bulk with some analysis of that entire table. This would certainly be a good workout for the poor analyst, but could scale well. I don't have a hostile inquiry here yet so I don't know which questions might be asked.
The outcome would be that we can defend the data as "as truthful as we can make it" by showing every edit to the inquiry.
Closing thought on the Sentry logs. I understand that the built in Sentry logging provides the ODK core team with valuable usage and error reporting.
I'm not sure whether these logs are a good place for a submission edit log (likely not), but if we rethink logging and who accesses and analyses all kinds of logs, this is another source.
As a maintainer of a self-hosted ODK Central instance, I would benefit from the insight gained from Sentry logs: is my server OK, which projects/forms are used (can I close them, did I migrate everyone to a new form etc).
Sentry is great for server issues, as it yells at me via email in real time about issues requiring my attention.
Central logs are great if I need to go back and audit the change history of a submission.
Therefore my needs are:
ODK Central logs accessible via API are ideal for submission edit logs.
Having an optional second Sentry instance receiving server errors would retain ODK core team's monitoring while also giving me as the maintainer insights I need to act on.
Sentry is an error-logging service and is really just a way to aggregate what each self-hosting administrator can get from their local logs so that we can act on it. There's no usage information tracked other than incidentally (if a piece of code crashes, that's an indicator that it's used).
The nature of the issues are typically such that you'd have to either patch the server yourself or file an issue. This is really stuff that's more actionable for the dev team. The only exception I can think of is unfortunately an issue you ran into -- where you hit some kind of database issue that locked everything up in a way that the server would still look "up" to most uptime monitors. We haven't seen that one since.