Context
A while ago @rsavoye made osm-fieldwork, which includes some utils for calling the ODK Central API (OdkCentral.py).
We use this in the Field Mapping Tasking Manager, but now that pyodk exists, it would be nice to combine efforts and contribute there instead.
Issue with sync methods
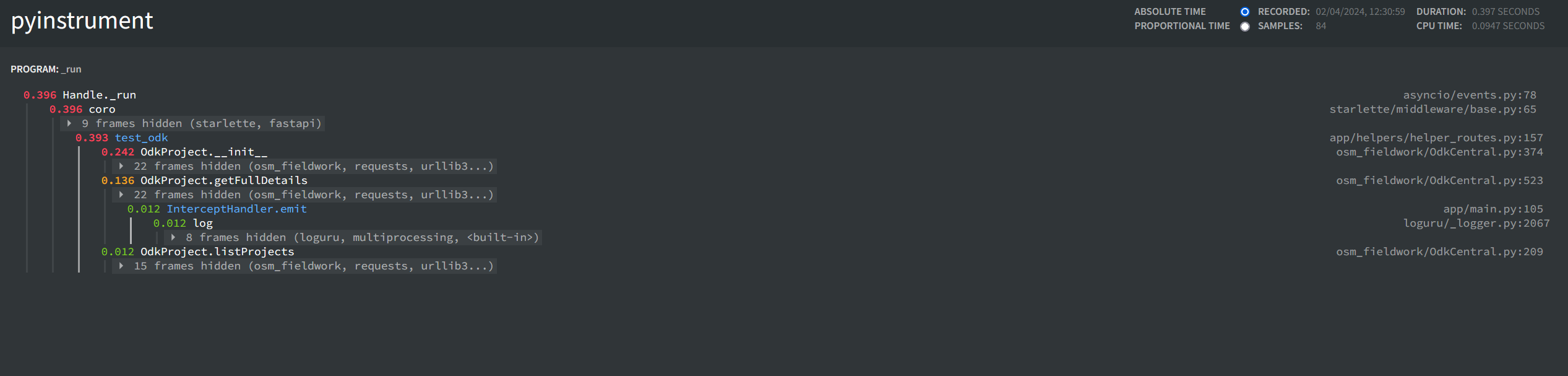
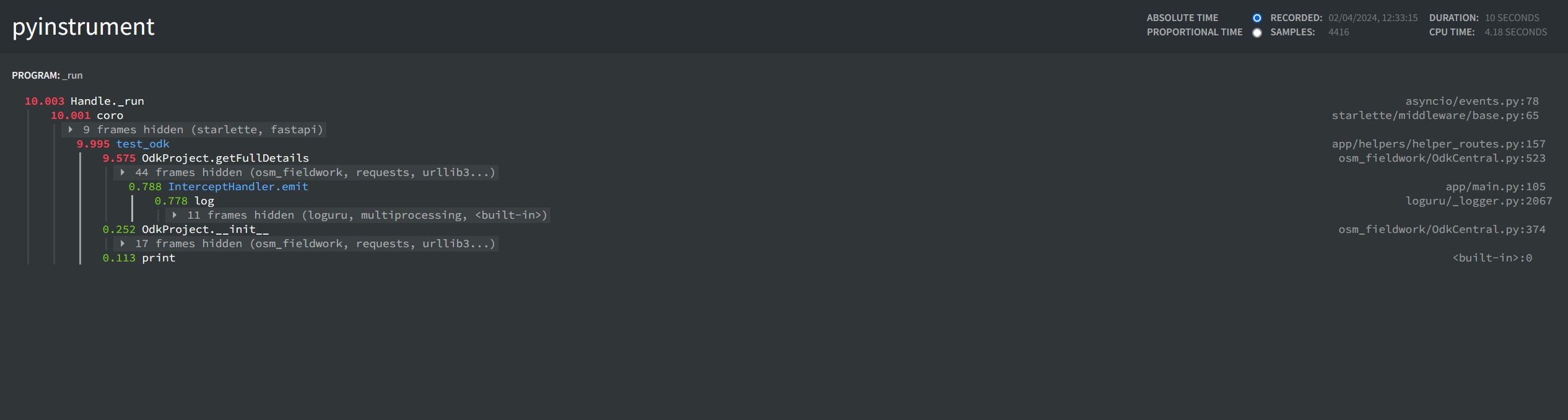
An issue we have been facing with osm-fieldwork is that making multiple Central API calls can be quite slow if not done concurrently.
Our use case is creating 10's to 100's of forms via the API, uploading attached media, and creating appusers for the forms, which I understand may be atypical usage.
Possible solution with async
I believe that making the calls async would improve performance significantly, as requests can be made 'concurrently' (not really with async in theory, but in practice yes).
As I would be adding this to osm-fieldwork anyway, I was thinking now is a good time to start contributing to pyodk instead.
Request
Would there be any interest in me adding async support to pyodk?
Does anyone in the community or dev team (@Lindsay_Stevens_Au) think this is valuable for the project?
Of course this would mean replacing requests with something like aiohttp or httpx, and would significantly change the usage of pyodk, requiring await to be used on each method call.
There may be a way to design this so that sync usage can be preserved, if preferred. Perhaps via a different import but sharing mostly the same logic underneath.
Related Info
We would be likely to add Entity support to osm-fieldwork in the very near future too, so perhaps we could help with https://github.com/getodk/pyodk/issues/62 too.