Publishing submissions to google spreadsheets halted as google spreadsheets has reached maximum 2Million cells.
v1.4.12 Production Ubuntu 14.04 Tomcat6 Postgresql9.6
Large data sets of geographic points
I have set up a new publisher to G..spreadsheets which is Streaming New Submission Data ONLY and receiving the new data - however I have a set of data between 3/aug/2018 and 5/sep/2018 which i can't retrieve via G.. sheets... is there anyway to pull the data from a filtering of the submissions... my methodology of updating my database includes Microsoft queries and Microsoft excel to manipulate data and it is the http pointers to the blobs in the ODK Schema that is important re replicate... I can get all the other data via SQL on the ODK schema but the http pointers I cant replicate http://192.168.0.1:8080/project/view/binaryData?blobKey=LEGEND_L_V2[%40version%3Dnull+and+%40uiVersion%3Dnull]%2FLEGEND_L_registo_parcelas_cduats[%40key%3Duuid%3Aa55c97de-1840-40c8-9261-0be549eefaa8]%2Frecibo_image
ANY HELP PLEASE
Hi, @TerryMud!
On paper, you should be able to run ODK Briefcase and export data using date filters, although you'd need to first pull every submission (Briefcase handles that but I assume it would take a long time/space to do).
If this is a reasonable approach, you could export the dates you need and merge data into your current workflow.
If this is not feasible we could try to reverse engineer those links using SQL queries. I think I could be of help with that too, but if Briefcase is an option for you, I'd try that first.
Thanks ggalmazor I tried the briefcase option but doing so it pulls down the actual image file and dumps it in the media once exported, I lose the pointer to the blob in the ODK schema which I use in Vfront to display the images so we can check documents and adjust the associated attribute data if required.
It would be handy if I could filter the submissions in ODK and only publish the filtered set....
I'm thinking of building a VM and replicate the db and aggregate site and deleting those instances already parsed into the public.db from the odk_prod,db for the one form and publishing to google sheets but that is a long way round I have 1324 submissions missing
Hi, @TerryMud!
Would the filters on Aggregate work for you?
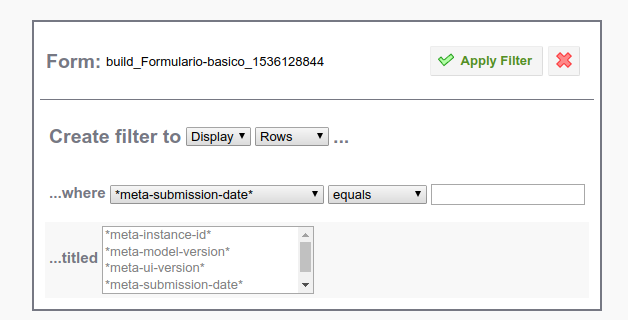
If you check the "Display metadata" checkbox on the left, you can define a filter using the *meta-submission-date* field. Then you could export/publish only those.
The trick to filter dates is to format them like Java wants them (ISO8601 format). This is an example: 2018-09-05T08:00:00.000 (note that we use a T to separate the date from the time)
I did try the filters yes, presuming that when publishing it would only publish the filtered set, unfortunately it didn’t and tried to publish the whole set again. I used another field to filter on, date survey performed. I’ll try on sub-date to see if the publisher acts differently.. I’m inclined to think it won’t but will try. Thanks
Have you tried to export to a csv file, instead of publishing? It should use the filters and you'll probably get the links you need.
Edit: I've just tried with a form on the sandbox and it seems to actually filter the output correctly. You'd need to save the filter, give it a name, and then select it when exporting.
Yes tried that too, thought it was going to work but a repeat group in the form gives the http pointer to a group output of names using the parent key of the blob reference rather than the “_UIR”
Will filter this where group count = 1 which will recover most of the data though thanks
1 Like
Anyway, I've decoded the URL into this:
http://192.168.0.1:8080/project/view/binaryData?blobKey=LEGEND_L_V2[@version=null and @uiVersion=null]/LEGEND_L_registo_parcelas_cduats[@key=uuid:a55c97de-1840-40c8-9261-0be549eefaa8]/recibo_image
(it doesn't feel impossible to recreate)
If I interpret this correctly, this is a URL to get the blob on a field called recibo_image of a group called LEGEND_L_registo_parcelas_cduats with UID uuid:a55c97de-1840-40c8-9261-0be549eefaa8, from the form LEGEND_L_V2.
If you send me the blank form, I could probably recreate the same exact row structure you need using the SQL queries Aggregate uses to prepare the data publication.
That sounds like the answer I was searching for... I have tried a few sql queries using concat() and the uuid of the image as the output is similar I managed to get some to work but others have been truncated as >255...
It’s a bank holiday here tomorrow and long weekend so will be back at the office on Monday now and can send through the form
Thanks Terry
1 Like
Great, I'll be around on Monday 
hi sorry I have been in a meeting all morning and just got out... are you still available
to help me get this data out of the ODK
Sure! I think I'd need the curent SQL you're running and the blank form so that I can replicate the db structure in my local PostgreSQL instance.
what I post here is not what I have on my screen and I don't understand what is happening
Hmmm, maybe Discourse is interpreting some of it as markdown.
You could try to save it into a txt file and attach it to a comment.