1. What is the problem? Be very detailed.
Some of our researchers want to take ODK survey data in Hindi or other major Indian languages. (Hindi is fourth largest speaking language of the World). We took test data in Hindi and sent to Aggregate. On Aggregate, it is showing the data values in Hindi well but;
1- Truncating the words after a limit in textual entry (We may not want this word or character limit also).
2- When we export data from Aggregate site in .csv through Export tab or through Briefcase utility, the data in Hindi language got disturbed or ruined. So changing the ODK interface in Hindi, getting the Label and Hint in Hindi will go waste if we can not capture and get data values also back in Hindi (This may be true for other major Indian Languages also). So where is the problem and how to get rid of it.
3- Data Name also not accepted in Hindi or in other languages.
2. What app or server are you using and on what device and operating system? Include version numbers.
Latest ODK Collect App and Aggregate setup on Ubuntu OS with PostgreSQL database. Forms designed in Build site.
3. What you have you tried to fix the problem?
I tried to export in JSON format and converted the JSON to .xls using various online free converters (may be risky) then I got the Language correctly in Excel.
4. What steps can we take to reproduce the problem?
Removing the number of character limit in text entry.
Indicating cause and solution of problem for getting data exported back same as entered in other than English languages.
5. Anything else we should know or have? If you have a test form or screenshots or logs, attach below.
Hopefully some of the following helps.
"By default, Aggregate's datastore layer limits text values to 255 characters or less. If a submission includes a value longer than 255 characters, those additional characters are not saved in the database and no warning is shown... It is possible to set the desired database field length for a particular question. This value can go up to about 16000 UTF-8 characters but the datastore storage efficiency may get worse as the value increases." [see Increasing Aggregate Field Length in the docs]
Are you trying to open the CSV in Excel? See the following post:
I copied some Hindi text from Google Translate was able to run it through Aggregate and open it up in Excel following the below but using Unicode (UTF-8) for the File origin, and I think it's showing correctly:
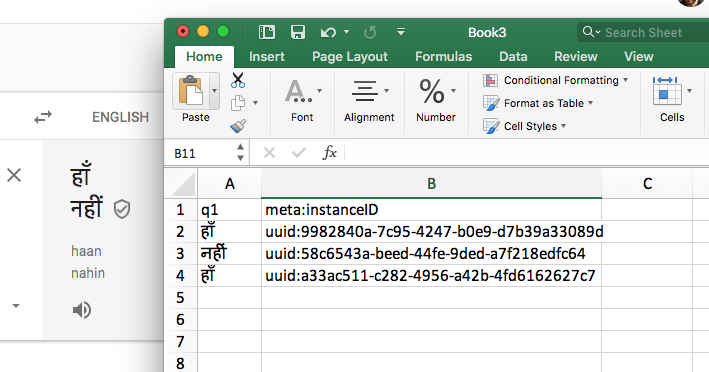
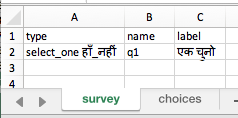
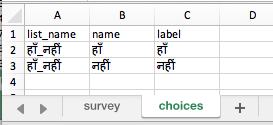
I was not able to get the name column on the survey tab to accept Hindi characters from Google Translate. I was able to get the name column on the choices tab to accept.
It might be worth taking a look at what functionality ODK Central offers instead of ODK Aggregate?
If you would like to help complete or improve the translations of the various interfaces please contribute via:
Dear @danbjoseph
Thank you very much for so detailed and prompt reply.
1- The solution suggested is working fine
2- However, using the LibreOffice as suggested by @Venkatesh_Raghavan (I consider him as our our Open Source mentor) is more convenient, robust and easy to use .csv so I can fairly say "Long Live Open Source!!!!!!!!!!"
2- About 'Data Name'- I tried it in "build.opendatakit.org website but in Survey Tab also this 'name' column will/should not accept any other language than English (I think so). However it may have reasons and not a big problem also.
3- We have already translated QGIS and ODK on Transifex in Hindi (updates are required) Enketo has not been tried as we are aware of the advantages of Enketo in standalone manner.
4- The truncation limit enhancement we will try soon.
Thanks again to all for kind support!
Harish