Hopefully some of the following helps.
"By default, Aggregate's datastore layer limits text values to 255 characters or less. If a submission includes a value longer than 255 characters, those additional characters are not saved in the database and no warning is shown... It is possible to set the desired database field length for a particular question. This value can go up to about 16000 UTF-8 characters but the datastore storage efficiency may get worse as the value increases." [see Increasing Aggregate Field Length in the docs]
Are you trying to open the CSV in Excel? See the following post:
I copied some Hindi text from Google Translate was able to run it through Aggregate and open it up in Excel following the below but using Unicode (UTF-8) for the File origin, and I think it's showing correctly:
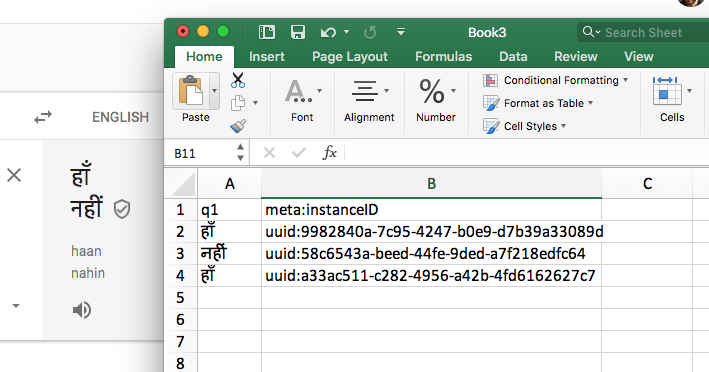
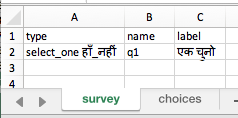
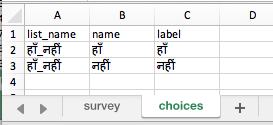
I was not able to get the name column on the survey tab to accept Hindi characters from Google Translate. I was able to get the name column on the choices tab to accept.
It might be worth taking a look at what functionality ODK Central offers instead of ODK Aggregate?