Hi Everyone,
I'm new to ODK, but we've spun up an ODK Central server on an AWS t2.micro instance for our teams to collect survey data. Our ODK Central server recently went down and it looks like our teams just hit it too hard all at once and used up all of our CPU credits (AWS T2 instances have limited "credits" that are used for bursts of high CPU load and refill when load is low, see plots below). It shouldn't have been that big a load - users have just been setting up their surveys. I've migrated us to a larger instance, but was wondering if anyone had 'best practices' for managing such systems. I'm planning to add some AWS CloudWatch alerts to let us know if we're running low on credits or disk space. I'm also trying to collect information from our teams about their planned usage. Does anyone have any other ideas for how we can minimize downtime? In addition, what are some of the more expensive (in terms of CPU load) tasks that our users might perform on the server?
Thanks in advance for your advice!
Cheers,
Rob
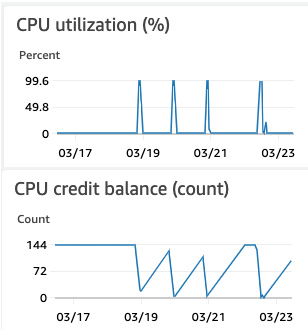
Central is primarily RAM bound, even for exports, so I'd recommend you monitor RAM/swap utilization and disk utilization (because of this tmp file issue). You'll need to use the CloudWatch Agent to get these metrics.
It looks like you are seeing regular spikes. What is happening at those times? Do you have backups configured? Is everyone sending submissions at that time? Log into the machine and run htop and docker stats and see what happens at those times. Checking your logs with docker-compose logs is also a good idea.
It might also be good to move your database from EC2 into RDS to gain continuous backups of the data (although you should still backup the EC2 machine) and more performance.
As far as minimizing downtime, multiple Central instances that write to one database which also has a replica is the best way to do that. It's not very straightforward for most people to do that. A reasonable alternative is to get a beefy machine, monitor performance, and adjust accordingly. Or use ODK Cloud, and all these problems go away ![]()
Thanks so much for your quick response and helpful suggestions!!
I'll set up the CloudWatch Agent as you suggest. I'm currently looking into what's happening at those spikes and will try to catch them in progress next time. We are doing backups, but it doesn't seem to use that much CPU. Thank you for pointing out the tmp file issue. I'll keep an eye out for that.
That's a great suggestion about moving the database to RDS. That might be a good way for us to go in the future.
In the short term we'll do as you suggest, upgrade the instance, monitor and adjust. Thanks for mentioning ODK Cloud again. We'll definitely keep that in mind and let you know if we decide to go that way.
Cheers,
Rob