I have been working on a R package for a complex multi-country project that involves a quite large amount of different sub-studies ranging from a pragmatic cluster randomised controlled trial (with follow-up at 3 different time-points) to qualitative studies, while linking data where possible between several of the sub-studies.
I would like to first acknowledge the fact that I fully benefited from the amazing amount of resources shared by the ODK community. I took most of my inspiration from the concepts described in the Electronic Data Management in Public Health and Humanitarian Crises. Upgrades, Scalability and Impact of ODK preprint written by the LSHTM and ODK teams, and I am extensively relying on the very well documented ODK Central API and ruODK package. Therefore, I am not presenting new ideas here, but I am illustrating how these different blocks can be interconnected and implemented for handling complex setup in a very efficient way (and much more than what I briefly present here).
My own code is publicly available on GitHub, although it is still a work in progress and is very project specific (I am planning to improve readability, roxygen2 documentation and generalizability on the longer term when I have more bandwidth). I felt this would probably be more helpful to others to have the main outlines, as I think some of these elements could be re-used quite easily in other contexts. I will try to update this thread over time.
ODK Central structure
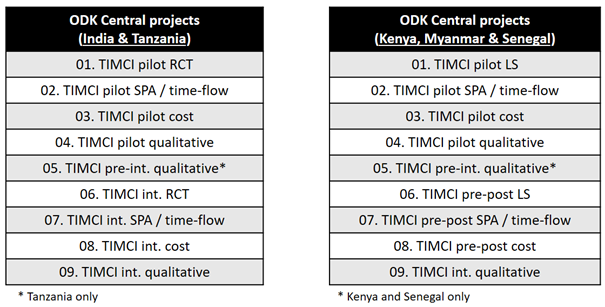
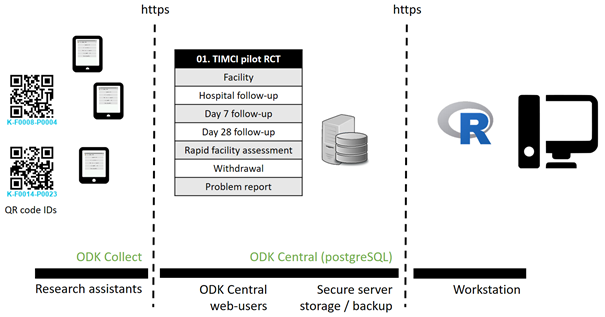
The XLSForm structure is kept as standardized as possible. Data that are country-specific are stored, where possible, in external CSV files.
The level of data protection is set differently for each project, e.g. access rights and permissions. In particular, projects that collect personally identifiable data (e.g. RCT projects) can rely on project managed encryption to ensure a higher data protection, but this then means new data management features available with release 1.2 of ODK Central will not be available for these projects, as submissions can no longer be viewed online.
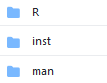
R project structure
Although data management tools will be available with release 1.2 of ODK Central, I still need a third-party application to perform data management activities that require complex interactions between different forms (e.g., checking that dates for a given participant are consistent within different forms). I used R for this purpose, mainly because ruODK was available and because R offers great data packages, and could have used Python alternatively. These tasks are highly project-specific and dependent on the data collection structure, so that they probably cannot be that easily transferred from one project to another.
-
Write a R package (you need Rtools40 to build R packages on Windows OS).
All core functions are stored in theRfolder (while themanfolder contains the auto-generated documentation fromroxygen2).
-
External datasets and media, and outputs such as Markdown files and Shiny apps are stored in the
instfolder. Markdown and Shiny apps are called through a run functions stored in R, using the system.file to define the path to these files

generate_report <- function(report_dir, rmd_fn, report_fn, rmd_params="") {
report <- system.file("rmarkdown", rmd_fn, package = "timci")
if (report == "") {
stop(paste("Could not find `", rmd_fn, "`. Try re-installing `timci`."), call. = FALSE)
}
rmarkdown::render(report,
output_format = c("word_document"),
output_file = c(paste0(report_fn, '_',Sys.Date(),'.docx')),
output_dir = report_dir,
params = rmd_params)
}
run_app <- function() {
appDir <- system.file("shiny", "myapp", package = "timci")
if (appDir == "") {
stop("Could not find `myapp` directory. Try re-installing `timci`.", call. = FALSE)
}
shiny::runApp(appDir,
launch.browser = TRUE,
display.mode = "normal")
}
- Environment variables
- Always check that your ~./.Renviron is at the root of your working directory when you run the code
- Use ~./.Renviron to set the variables used for RuODK setup (e.g., ODK Central URL, project IDs, form IDs, etc)
- Use ~./.Renviron to set all the context variables that may vary from one country to another
- To use
rmarkdownoutside of RStudio (e.g. in a batch),RSTUDIO_PANDOCneeds to be set in your ~/.Renviron file (since the rmarkdown package relies onpandocwhich is a document converter that can convert files from one markup format into another).
Data export
I rely on rmarkdown to perform and document all the following data export tasks:
Generate customised exports of the database
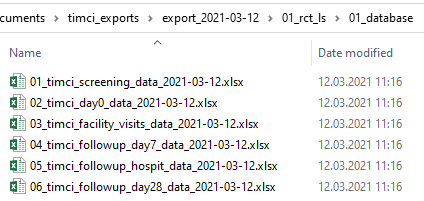
Store personally identifiable data in a secured way
When generating the data export, I separate and store variables that are identified as personally identifiable information in an Excel in a password-protected zip. I could have created a password-protected Excel, but the xlsx R package that allows this has some Java dependencies that make it less portable in general. I can also encrypt the project with ODK Central. Probably data security could be further improved, but as the zip is currently only generated locally, I feel this is a first step. I also hash IDs and will maintain a (restricted access) mapping between the ID codes given at data collection and the ID codes present in the de-identified database (not fully implemented yet).
Organise qualitative material that relates to a given participant in individual folders
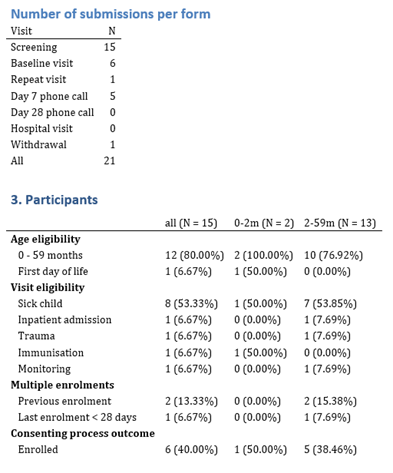
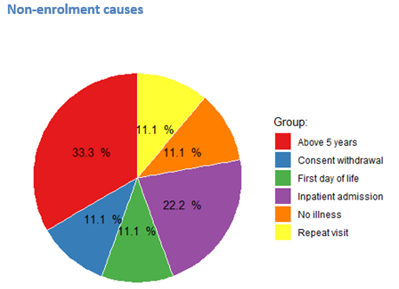
Generate automated quality check / monitoring reports

Data Management pipeline automation
I have used this approach on Windows OS with both R and Python codes to automate some of the data and server management via the ODK Central API and it works like a charm.
If you are using Unix, have a look at this example with Cron from the LSHTM.
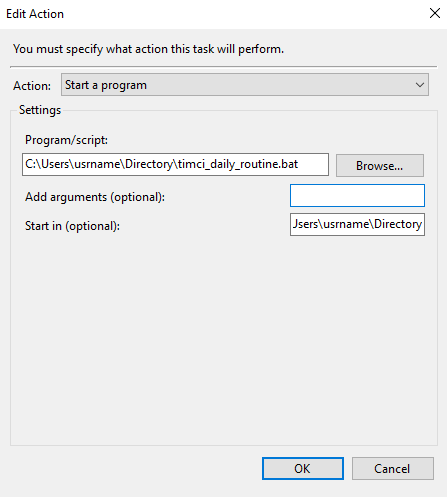
- I would recommend that you batch your R (Python or any other language) script. This may not be absolutely necessary, but I find this a very helpful intermediate step to debug and ensure that all environment variables / path definitions are properly set, rather than trying to run the script directly with the task scheduler.
cd C:\Users\usrname\Directory
"C:\Program Files\R\R-4.0.2\bin\x64\Rscript.exe" C:\Users\usrname\Directory\timci_run.R
PAUSE
- Call your batch with the Windows task scheduler
I have set the task so that it is run every day at a fixed time, but there are many more options to configure automation (inTriggers,ConditionsandSettingstabs)

Follow-up / longitudinal data collection
For the pragmatic cluster RCT, I have a first form for screening participants / collecting baseline data and three forms for collecting follow-up data. A CSV list of participants is generated every day from the baseline form (+ there is one follow-up form that is triggered by data collected at the first follow-up). The list is generated so that participants who have already successfully completed their follow-up, or withdrew from the study (this is collected in another form within the project), or who are outside of the follow-up window are not called.
Although I was very keen on using the ODK API to export data from the server, I was very hesitant to use it to modify files on the server, but it works so well that I feel this would be a shame to miss these functionalities. I use ruODK to retrieve the current version number of the form, then use the ODK Central API to automatically create a draft (empty – as I want to keep the XLSForm that is already published on the server), upload the updated version of the CSV, then publish the new draft having incremented the version number (I use a very small incrementing step for to be sure that I cannot confuse this for the manual update of a form).
Obviously this strategy for collecting longitudinal data cannot be used in all contexts, as it introduces a dependency on the ODK Central server for retrieving data.
Get form details
cform <- ruODK::form_detail(
pid = ruODK::get_default_pid(),
fid = Sys.getenv("TIMCI_CRF_DAY7_FID"),
url = ruODK::get_default_url(),
un = ruODK::get_default_un(),
pw = ruODK::get_default_pw(),
)
current_version <- as.numeric(cform$version)
Create a draft form
res <- httr::RETRY("POST",
paste0(ruODK::get_default_url(), "/v1/projects/", ruODK::get_default_pid(), "/forms/", Sys.getenv("TIMCI_CRF_DAY7_FID"), "/draft"),
httr::authenticate(ruODK::get_default_un(), ruODK::get_default_pw())) %>% httr::content(.)
Upload the new CSV created as a form attachment
res <- httr::RETRY("POST",
paste0(ruODK::get_default_url(), "/v1/projects/", ruODK::get_default_pid(), "/forms/", Sys.getenv("TIMCI_CRF_DAY7_FID"), "/draft/attachments/day7fu.csv"),
body = httr::upload_file(csv_fname),
httr::authenticate(ruODK::get_default_un(), ruODK::get_default_pw()))
Publish a draft form
new_version <- as.character(current_version + 0.000001)
res <- httr::RETRY("POST",
paste0(ruODK::get_default_url(), "/v1/projects/", ruODK::get_default_pid(), "/forms/", Sys.getenv("TIMCI_CRF_DAY7_FID"), "/draft/publish?version=",new_version),
httr::authenticate(ruODK::get_default_un(), ruODK::get_default_pw())) %>% httr::content(.)