The ability to randomize the order in which questions or options appear in a form is a well established technique to reduce introducing unintended bias in a survey, where exposure to previous questions may subconsciously influence a respondent's answers to subsequent ones, or options appearing at the top may be perceived to be preferable or more important. To avoid the later, ODK provides the ability to randomize the choice order so that each time your form is run the displayed order of the options in a select_one or select_multiple question will be different. Unfortunately, there is no handy equivalent in ODK for randomizing the actual order of the questions themselves. There are some techniques you can try to randomly order your questions, one of the most popular being a brute-force approach of creating all possible permutations of ordering, each in a different group, and then using a random number to only show one of the groups [see https://docs.google.com/spreadsheets/d/11LEhyjkRWryTKKfmlyTMWOUkKLDRnY9JDAOqgCzEE2M for an example]; each time the user will be randomly presented with a different permutation group. The main problem with this approach is that the number of permutations grows factorially: 3 questions - 1,2,3 - have 6 possible permutations: 123, 132, 213, 231, 312, 321; 5 questions have 120 permutations; 10 questions have over 3.6 million! You can reduce the number of presented permutations to a manageable size, but at the expense of true 'randomness' [sic].
This article describes a new technique to present an arbitrary list of questions in a truly randomized order each time you run the form. It scales linearly with the number of questions and doesn't involve a great deal of effort on behalf of the form designer to implement. So let's jump straight in... ![]()
1. Create a prescribed choice list
First, we need to create a select_one question (or select_multiple, it doesn't matter which) with a choice list that contains a list of numbers 1..N, where N is the number of questions we will be randomizing; lets say 5. The labels associated with each choice don't matter; we wont be using them, and this select question wont actually be shown(!). In our example the choice values must be: 1,2,3,4,5.
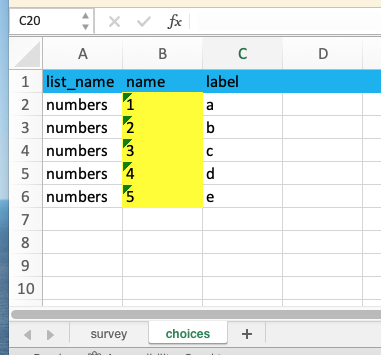
The real purpose of this select question is to generate a list of numbers - in the form of a XForm nodeset - which we can then randomize. By making the select's relevant = NO means this utility question is hidden and wont actually be shown to the user. Specifying a choice_filter = YES is a trick to force pyxform to generate an XForm with these choices turned into a secondary instance nodeset, rather than 'inline' with the associated XForm control. This step isn't actually required anymore due to recent changes in pyxform whereby all select options are now automatically expressed as secondary instances, but it helps for backward compatibility, and I found ODK Validate may still sometimes throw an error without it.

2. Randomly shuffle some numbers
Next comes the Secret Sauce® ![]() ... By applying a little ODK XPath black magic, we use the choice list nodeset we created above, extract just the numbers from it, feed this into ODK's randomize() function to shuffle the numbers around into a random order, and finally pull the now-randomized numbers back out into an 'array' for later use.
... By applying a little ODK XPath black magic, we use the choice list nodeset we created above, extract just the numbers from it, feed this into ODK's randomize() function to shuffle the numbers around into a random order, and finally pull the now-randomized numbers back out into an 'array' for later use.
![]()
This calculation probably needs some explaining:
once(join(' ', randomize(instance('numbers')/root/item[true()]/name)))
-
instance('numbers')/root/itemis actually the reference to the nodeset containing the original secondary instance containing all our choices, -
[true()]is a simple XPath filter that returns all the so-named nodeset 'items', each containing one of the choices (both the name and label), -
/namereturns just the name (ie number value) of each choice, -
randomize()takes this new nodeset (!) and randomly shuffles its elements. Normally this specialized ODK XPath function is used to randomize the display order of the choices in a select, but I'm re-purposing it here for my own devious exploits...
-
next,
join()collects all the elements out of the resulting randomized nodeset and puts them into space-separated string. Make sure to specify a single space for the separator. -
and lastly,
once()ensure we only run this calculation once() ever, otherwise we might clobber our original randomized list, which would mess things up.
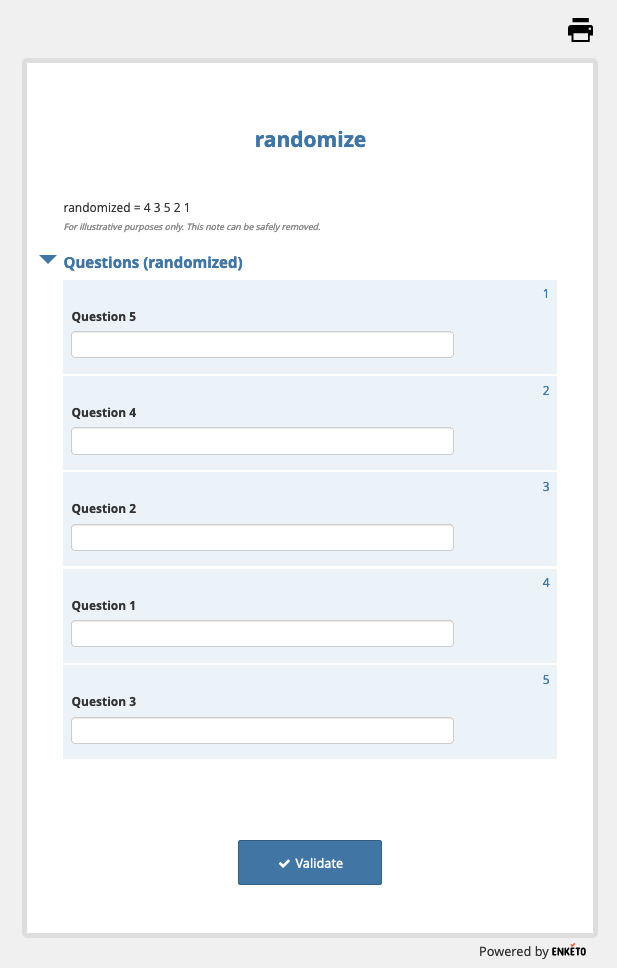
I now have a randomized list of numbers from 1 to 5; eg "2 4 3 5 1"
3. Repeat your questions (but hide most of them)
The next step is to put all the questions we wish to randomize into a repeat group, and then repeat this group the same number of times as the number of questions, in our case 5:
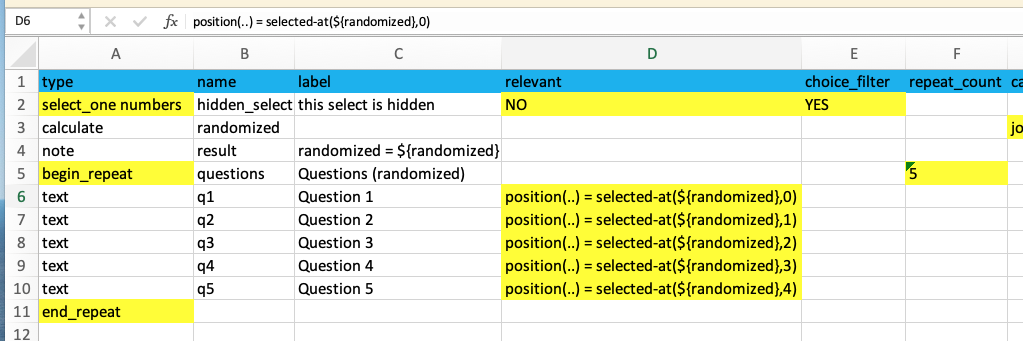
Leaving this as-is would just repeat the same 5 questions over and over again 5 times. However, what we do now is ensure that only one of the 5 questions is displayed during each repeat iteration, by adding a suitable relevant = ... condition to each question. Which specific question will be displayed each time is determined by the randomized list of numbers that we generated previously; specifically:
position(..) = selected-at(${randomized},0)
This relevant expression probably needs some explaining too:
-
position(..)is basically the current repeat iteration we are in: 1, 2, 3... -
selected-at(${randomized},n)is used to lookup the n-th element of our randomized 'array' of numbers. Its important to note that the selected-at() function is zero-indexed, so the first element of the array (ie the first randomized number) is at index 0, the next at index 1, and so on.
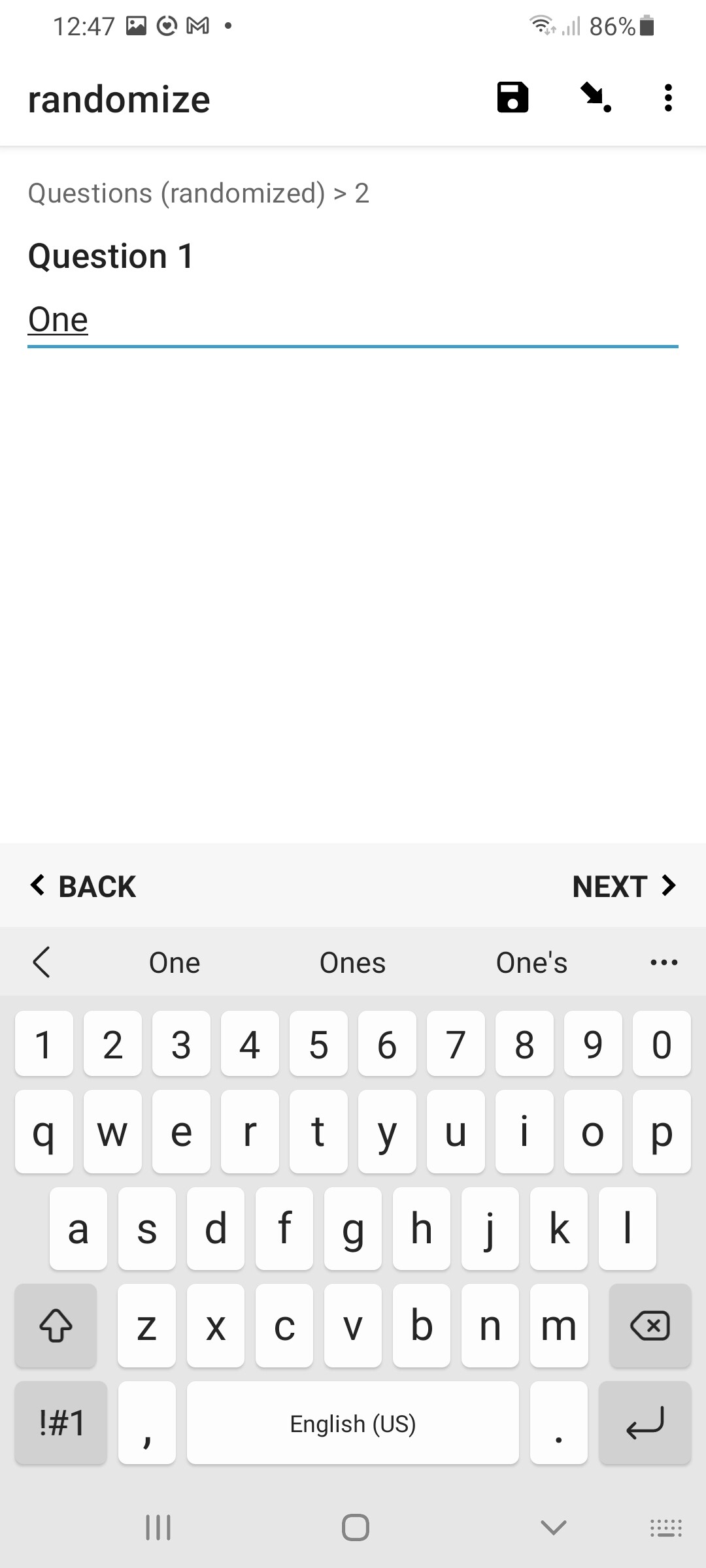
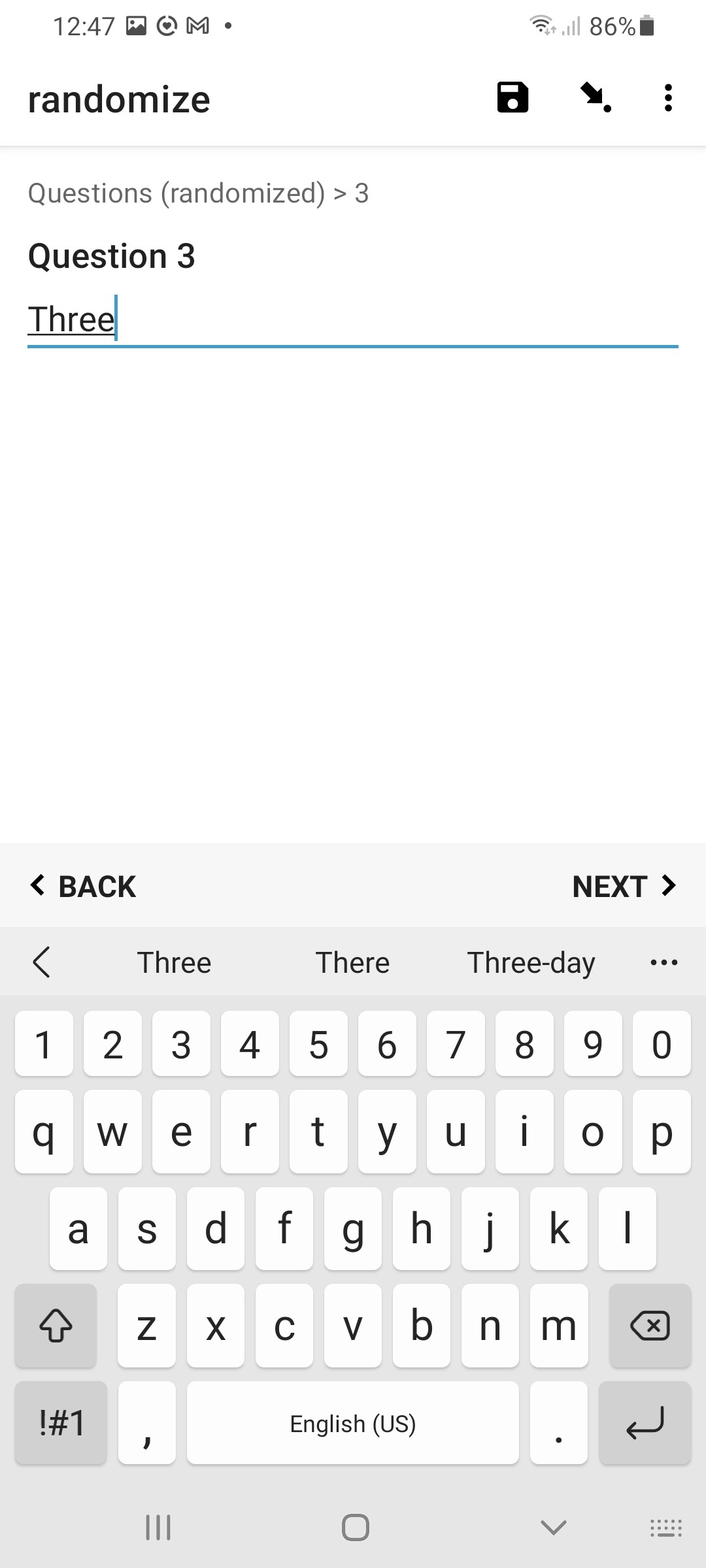
For each question we add an equivalent relevant expression, changing which element of the randomized array to check the current iteration against to decide whether to display that question or not. In this way, only 1 question is ever displayed during each iteration, and the order of the randomized numbers indicates which iteration the corresponding question will be displayed in. Re-running the form will generate a new random array of numbers, resulting in each of the questions now probably being displayed during a different iteration. Hence, the user is randomly presented each question in a different order. Ta-Da. ![]()
Result
in Enketo:
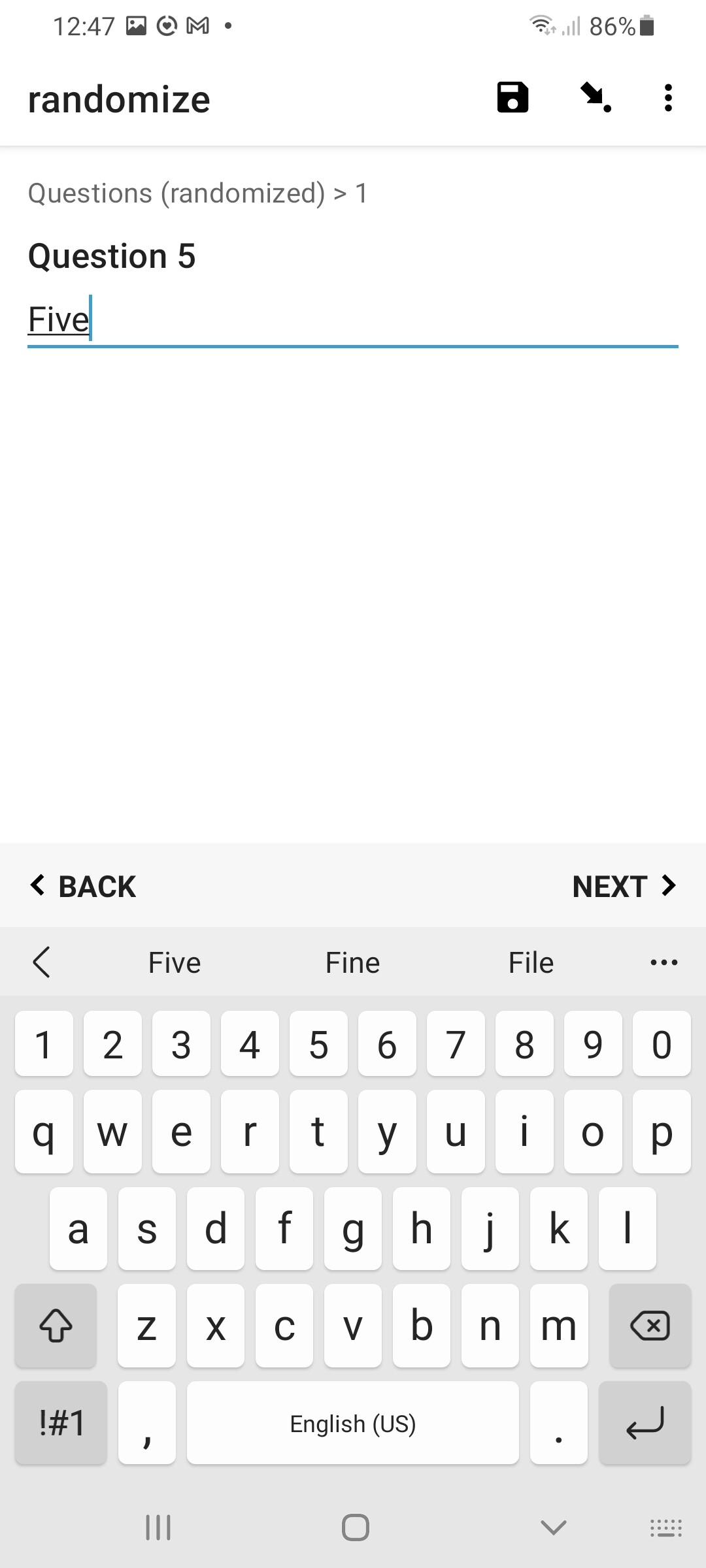
in ODK Collect:

...
Here is the final form, configured for 5 randomized questions. Hopefully it's obvious how to modify it for greater or fewer questions:
randomize.xlsx (9.9 KB)
Have a play around, eg upload it into XLSForm Online and run it under Enketo a few times to see the question order changes, and let me know what ya think! ![]()
Postscript
Please note this technique wraps your original questions in a repeat loop, consequently the final results that get pushed back up (to Central) will have all the question responses located in different iterations of the repeat group. The responses to each question are all in there, and only once, but you may want to do some post-processing to consolidate/flatten them all back out of the repeat.

Trivia
For some history, this grew out of something I was playing around with a few years back trying to do the same. Unfortunately, the solution I came up with back then worked fine for randomizing questions in Enketo, but it relied on a specific behavior of Enketo's XPath evaluation engine, which differs from ODK's javarosa engine. As a result, the randomizing form worked great for Enketo but didn't work at all in Collect, so I didn't post it. Fast forward to now, @Luisfer1492 asked me about this Enketo-only solution last week, so I dug it up over the weekend, took another look at it, and found a way to make it work for both! ![]()