Random sampling is an established statistical method to roughly assess a large population when sampling every single individual therein is infeasible, by instead assessing a much smaller unbiased random subset, such that if many such samples were drawn the average sample would accurately represent the overall population. From Wikipedia:
"In statistics, a simple random sample (or SRS) is a subset of individuals (a sample) chosen from a larger set (a population) in which a subset of individuals are chosen randomly, all with the same probability. It is a process of selecting a sample in a random way."
A perhaps more pragmatic description of what is - and more importantly what isnt! - a random sample, and one which alludes to why it's a bit tricky to accomplish in ODK Collect, has been given elsewhere in the Forum by @chrissyhroberts:
The basic requirement was to select a random sample of n entities from a list p long, without replacement.
i.e. if you had these items in the list
A, B, C, D, E, F
and you wanted a random sample of 3 items without replacement. then an acceptable sample would be
A, D, E
or
E, F, Bbut not
A, E, A in which there is replacement of A in the list after A is sampled the first time.
Practically speaking, generating a single random number between, say, 1 and 100 is easy. This number can then be used to pick one random sample out of your dataset, eg #42. However, if you want a sample size of 2, 3 or more, simply generating further random numbers like this wont work, because there is no guarantee you wont regenerate 42 a second time! This is why non-singular random sampling is a trickier problem - you must guarantee no duplicates.
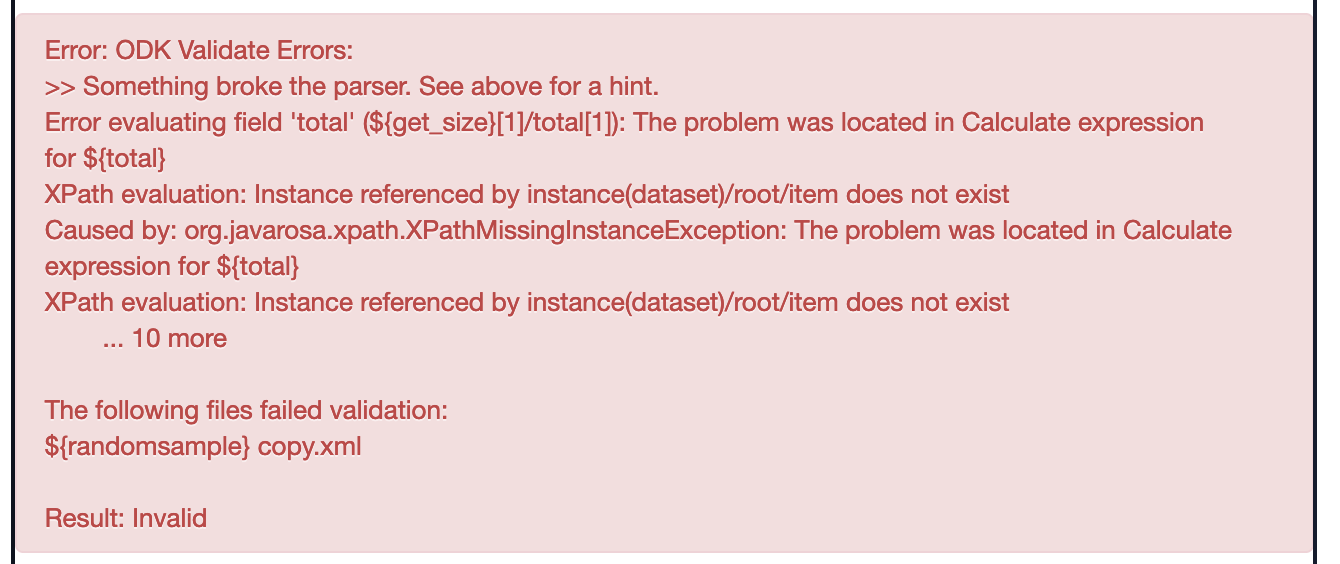
This article describes a new technique to extract an arbitrarily sized (with no duplicates) random sample from an internal instance dataset, exactly the same sort of form dataset that you might use to populate select_one or select_multiple questions. This approach directly evolved of my previous post here about randomizing questions, and utilizes much of the same logic.
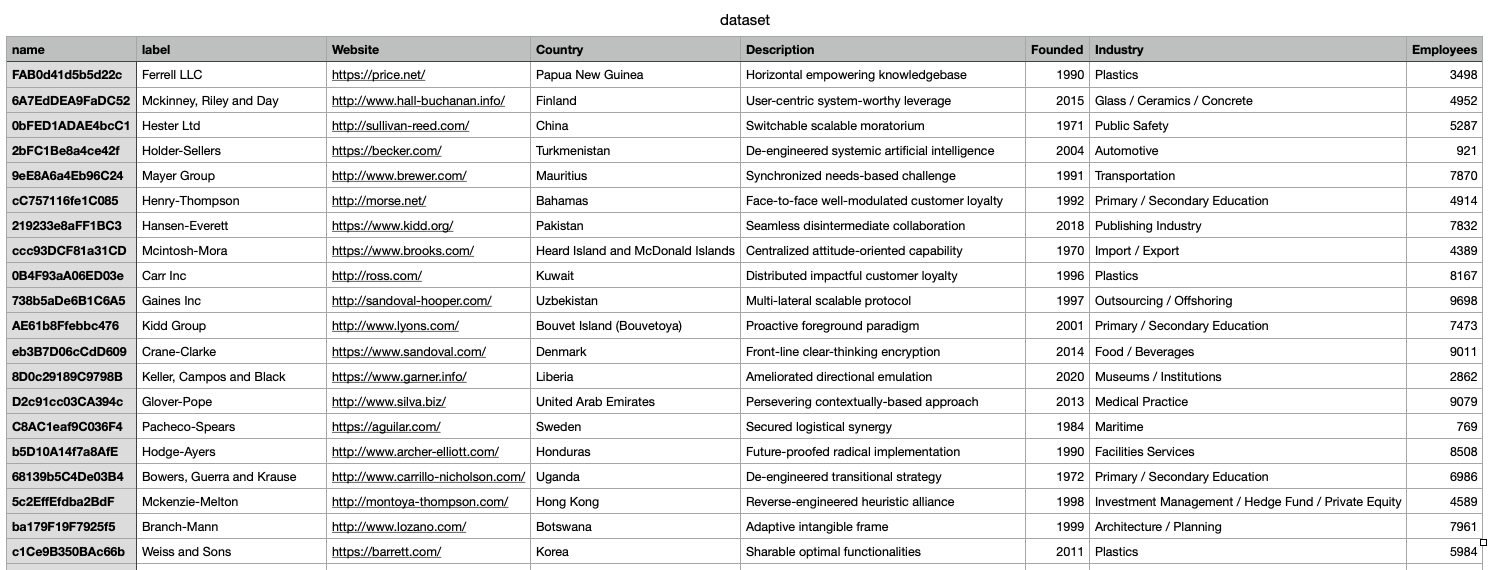
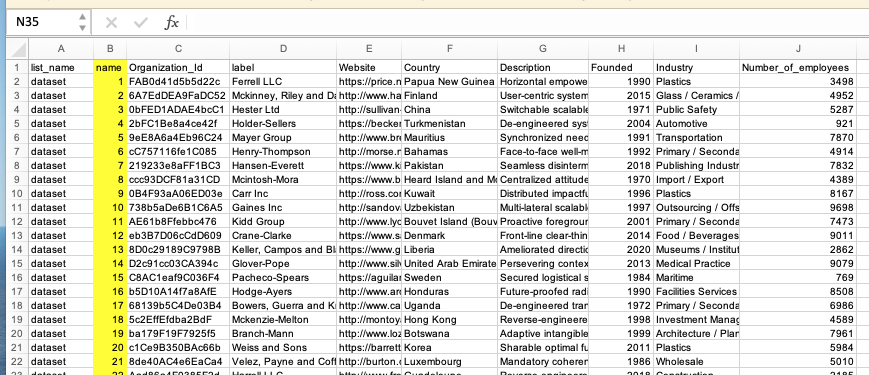
1. Ensure your dataset has a contiguous index
I'm using a generic dataset which I copied from here. The only important thing is that your dataset must have a field containing a contiguous index for each sample, from 1..N where N is the total size of the dataset. For simplicity, I'm using the regular XLSForm choices name field for this purpose. eg
2. Randomly shuffle some numbers
As with my randomizing questions solution, the next step is to apply the Secret Sauce® to randomly shuffle your dataset's index into an 'array' for later use:
once(join(' ', randomize(instance('dataset')/root/item[true()]/name)))
See Randomizing the order of questions for a more in-depth explanation of how this works.
After this, I now have a randomized non-repeating list of numbers from 1 to N; eg "22 42 3 15 10 ..."
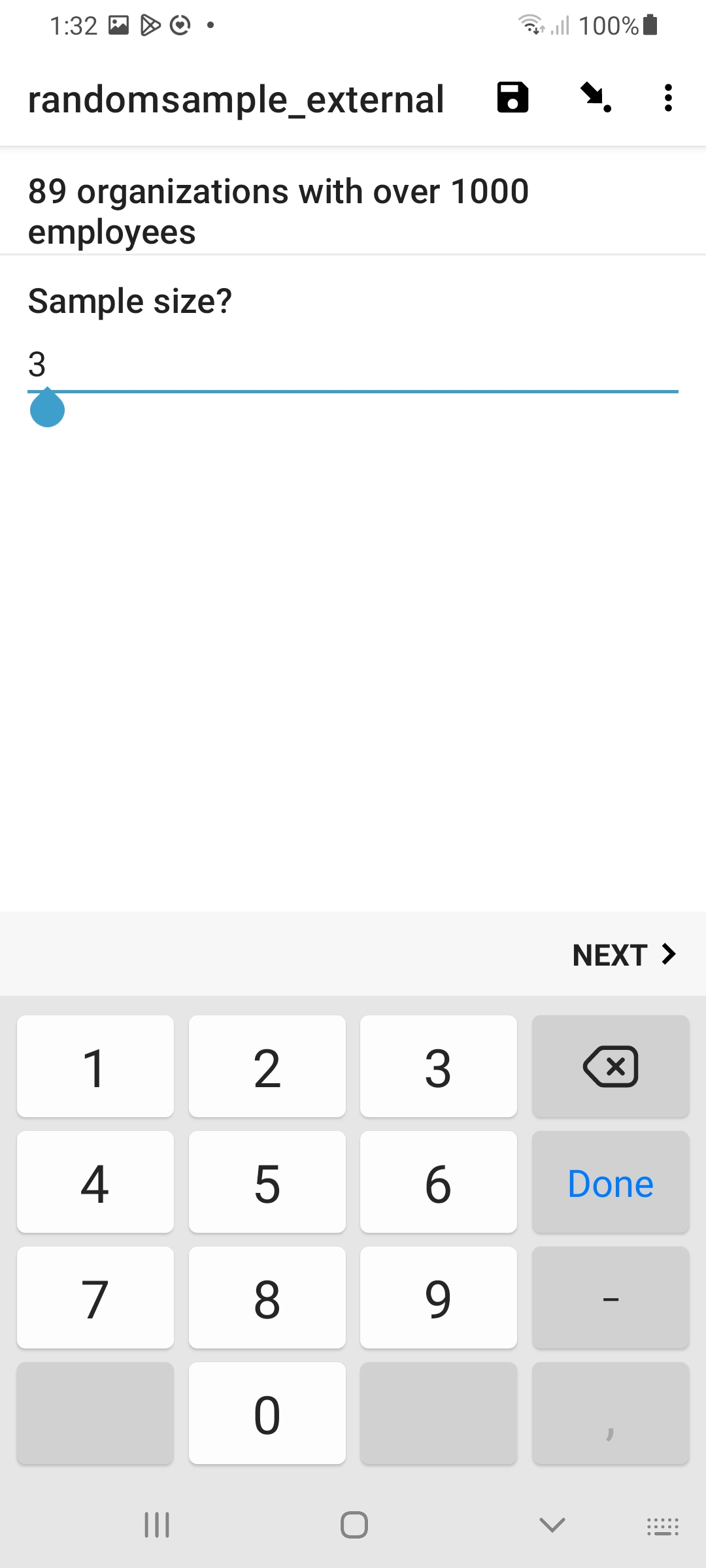
3. Pick your sample size
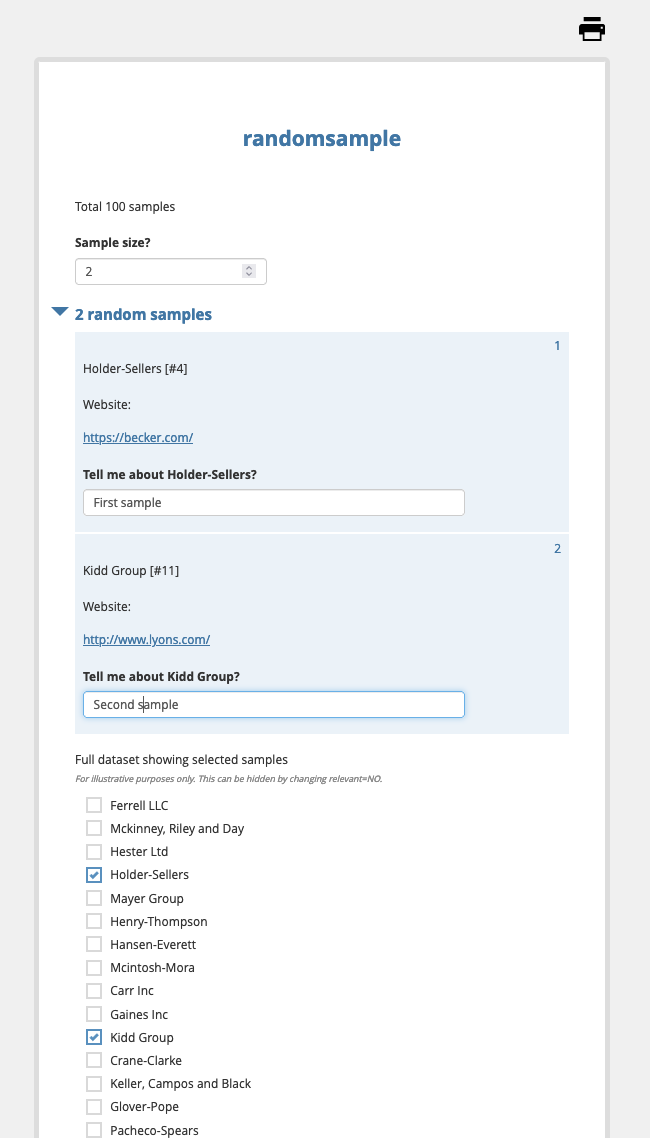
Next determine what your sample size is going to be. It should be at least 1 but no more than the total number of samples in your dataset. To determine the latter, you can use an XPath trick to count() the internal instance dataset size.
count(instance('dataset')/root/item)
Normally count() is used to count the number of iterations of a repeat group, but in general it can be used to count the number of elements in an arbitrary nodeset, which internal datasets are. So in our case, count() gives us the total number of items in our dataset.
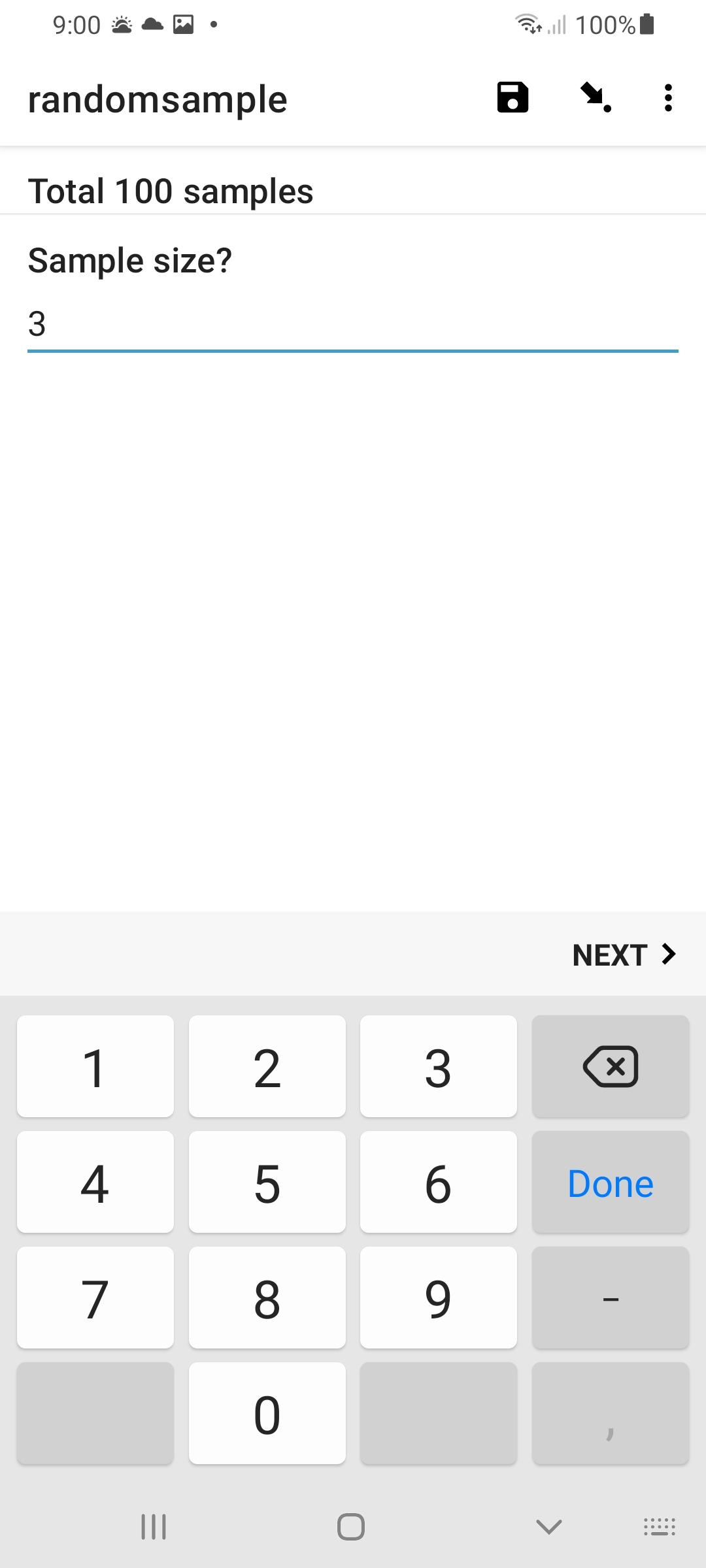
How you determine the sample size is entirely up to you; it can be a fixed value for your specific application, or it can be determined by other data acquired by your form, or it can simply be user specified, as shown here.
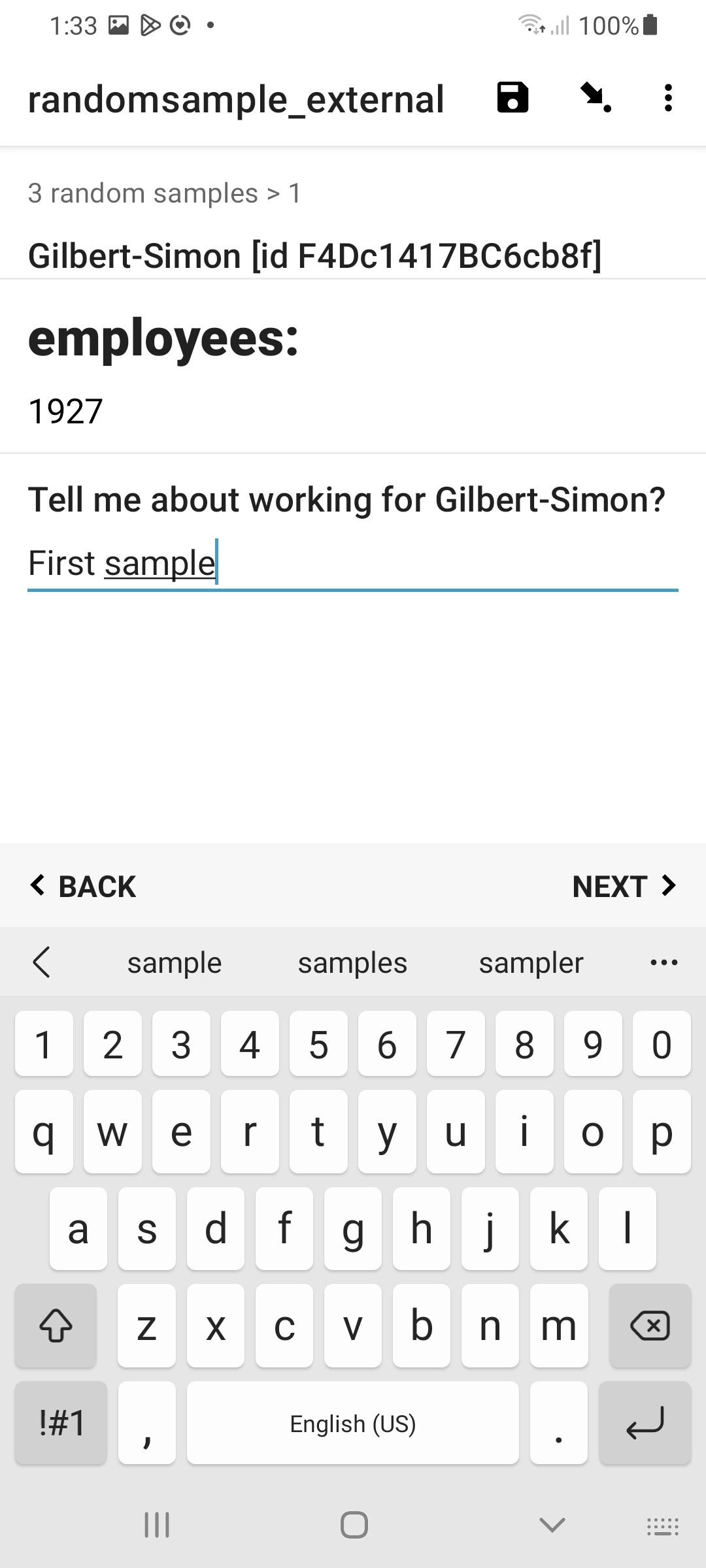
4. Extract a random sample set using a repeat group
The next step is to pull each of the random samples out of the dataset, according to the now randomized indices calculated above. For each repeat iteration, we get the index of the next (random) sample of interest by looking up the corresponding position in the randomized array:
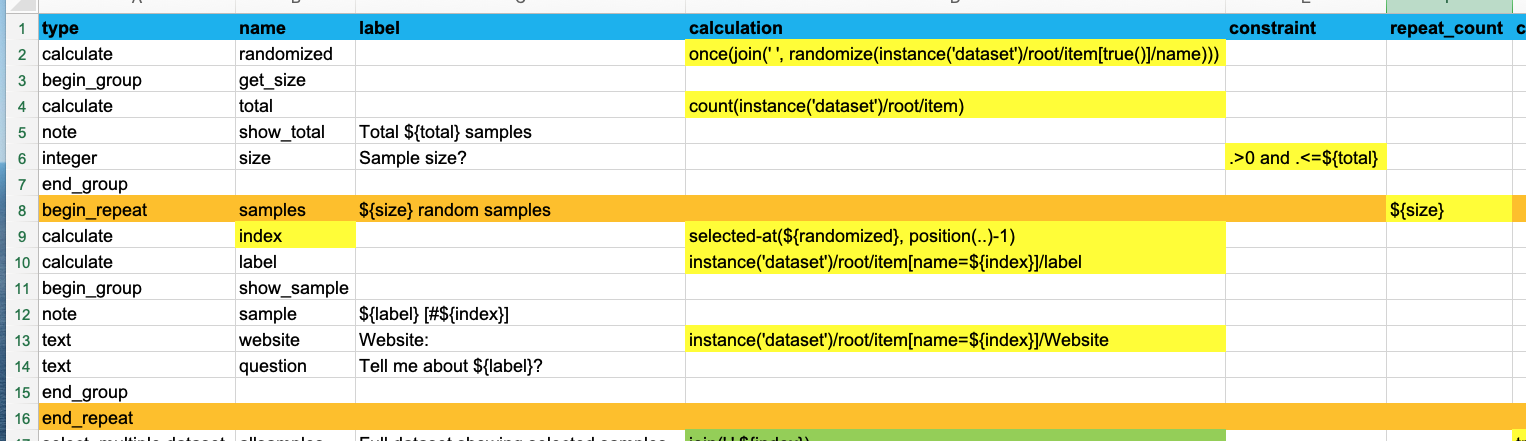
This calculation probably needs some explaining:
selected-at(${randomized}, position(..)-1)
-
position(..)is basically the current repeat iteration we are in: 1, 2, 3... -
selected-at(${randomized},n)is used to lookup the n-th element of our randomized 'array' of numbers. Its important to note that the selected-at() function is zero-indexed, so the first element of the array (ie the first randomized number) is at index 0, the next at index 1, and so on. Hence why we subtract 1 fromposition(..)
So during each iteration, we get the index (ie name) of a different (and non-repeating!) item in our dataset. If our randomized list of numbers is "22 42 3 15 10 ..." then in the first iteration we get index 22, the next iteration we get index 42, and so on. In this way, each iteration targets a different item in our dataset. We further limit the total number of repeat iterations by setting its repeat_count to the sample size. So we basically keep pulling the next randomized index out of our array till we reach the desired sample size.
Once we have the index of a specific (random) sample, we can lookup whatever desired field data we want about it, with calculations of the form:
instance('dataset')/root/item[name=${index}]/label
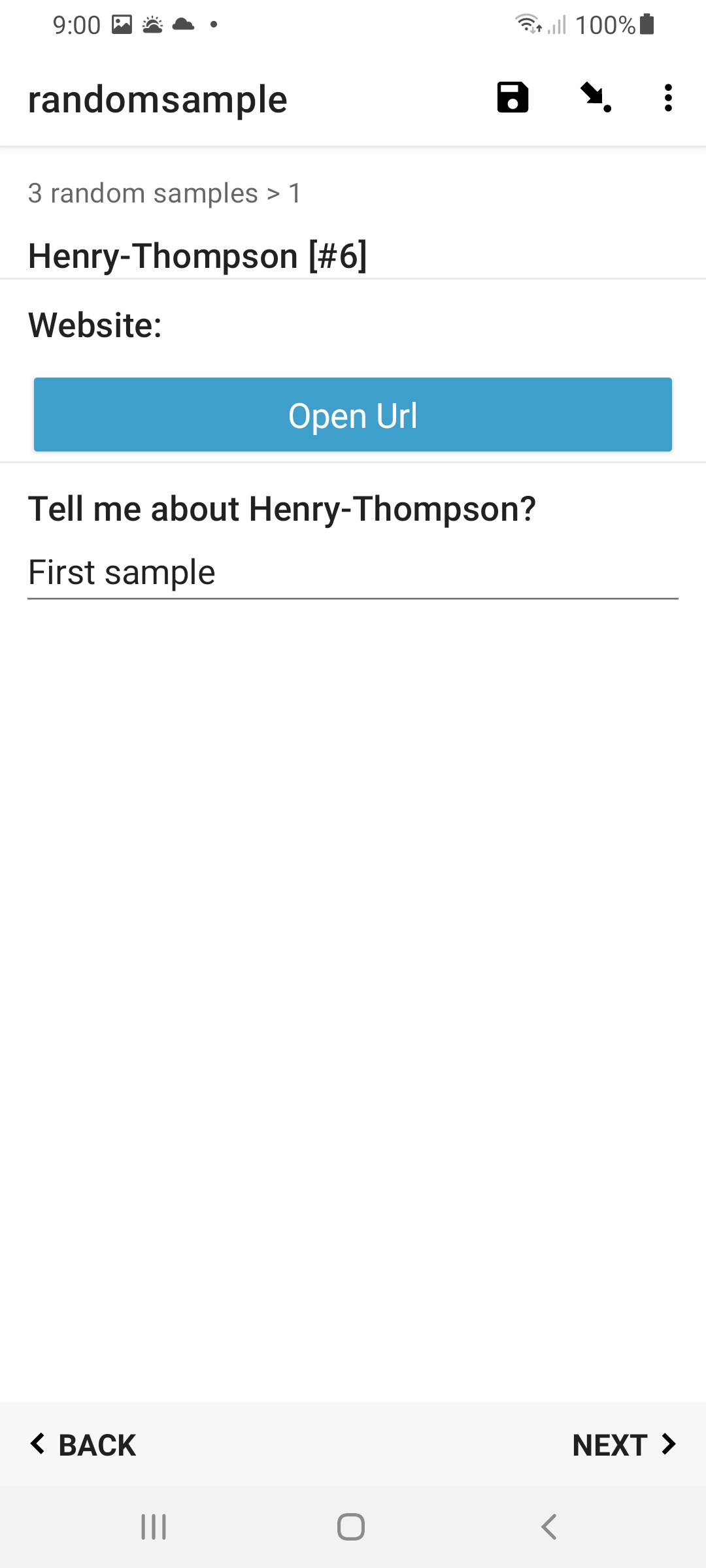
This is actually no different as you would normally do to reference values in dataset, as already described in some detail here: https://docs.getodk.org/form-datasets/#referencing-values-in-datasets. Basically, replace 'label' above with whatever column field in your dataset that you wish to get the value for this - ie [name=${index}] - specific sample. For example, 'Website'.
5. [Optional] Show the random sample
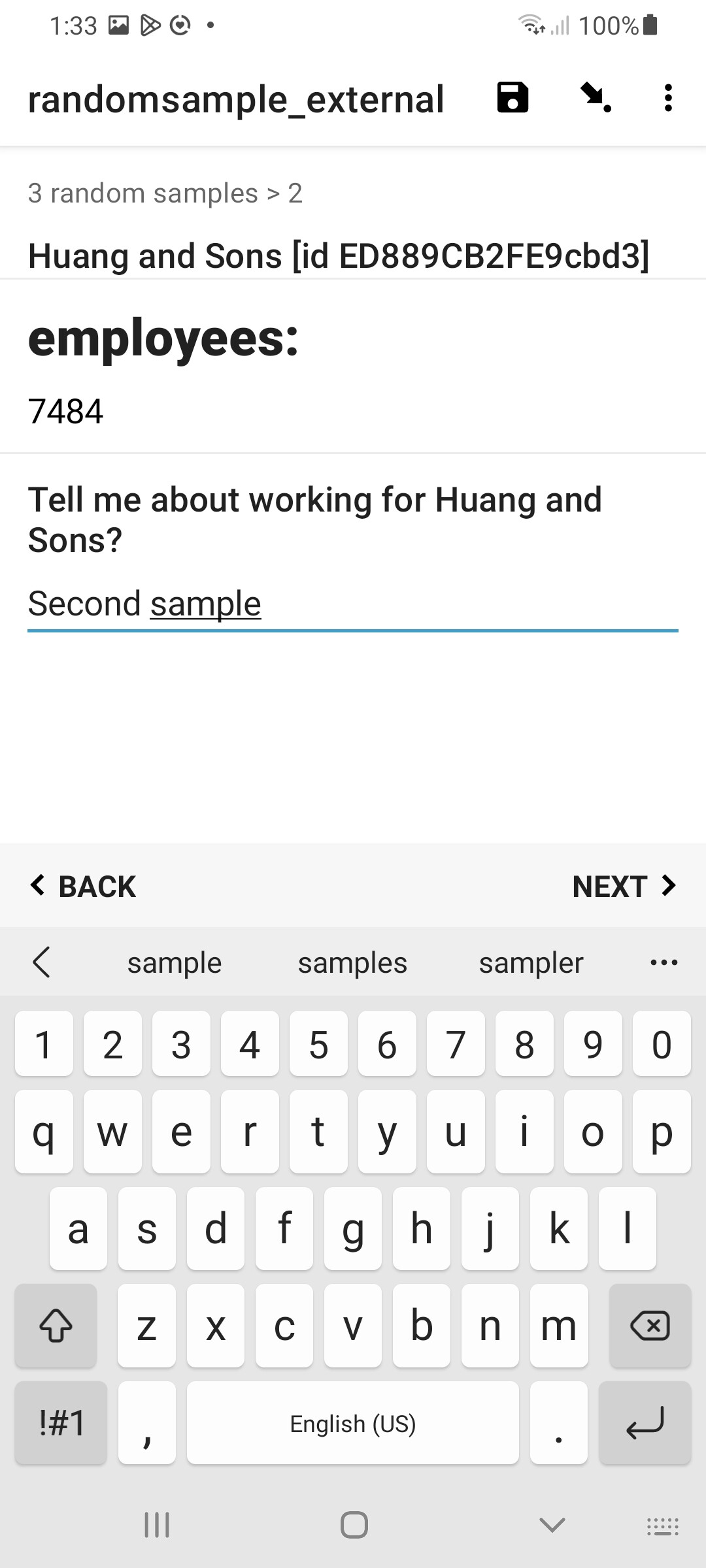
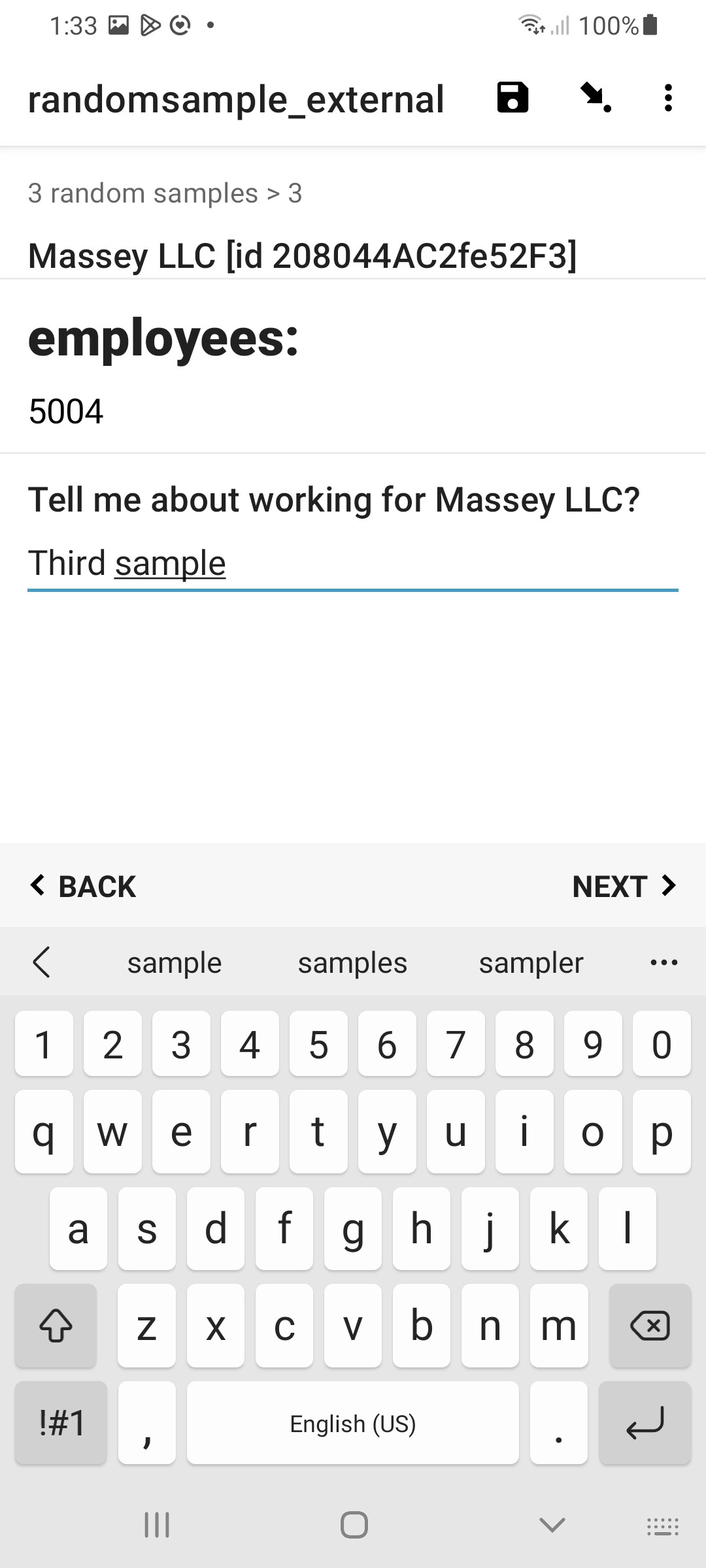
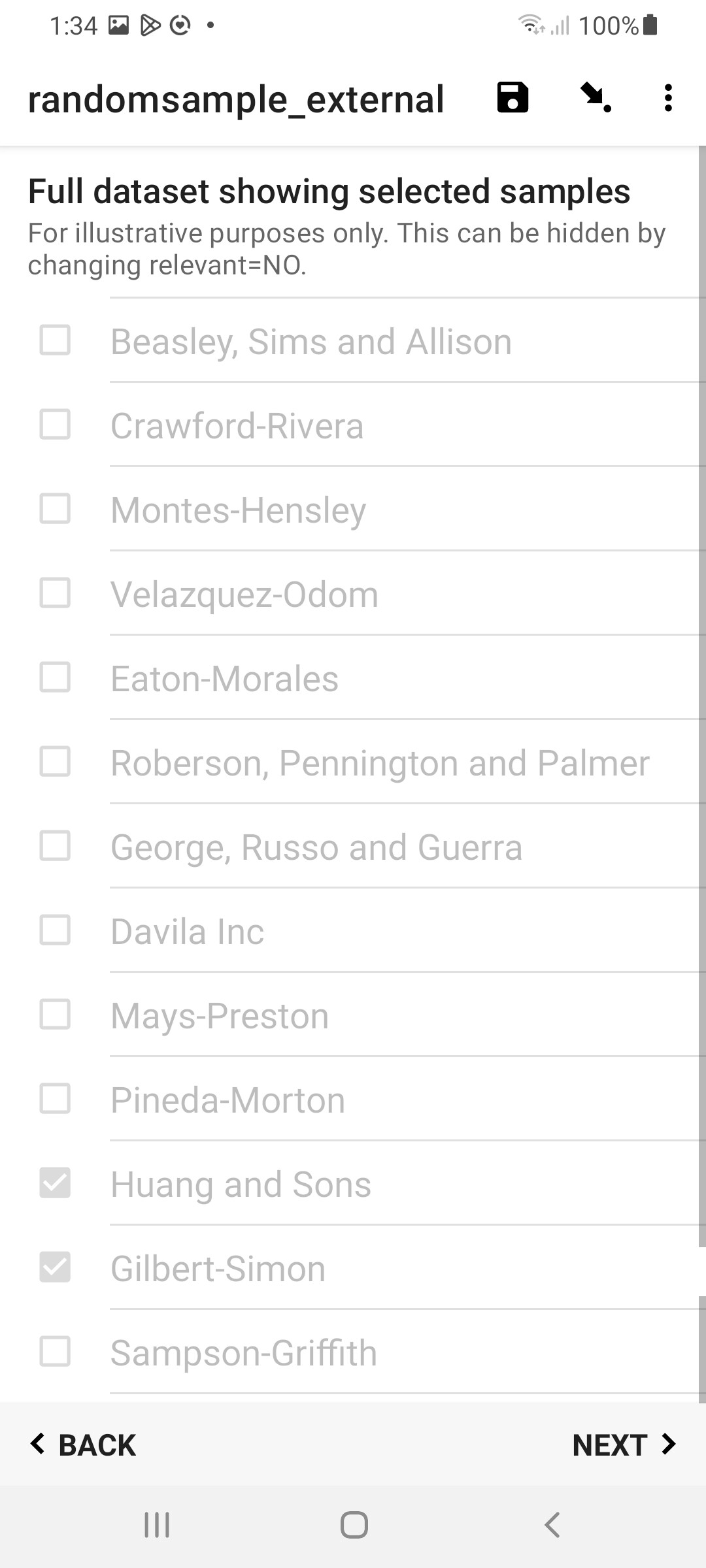
At the end of the form you could choose to display a select_multiple question with the entire dataset. This is purely for display purposes, to show all the samples and indicate which have been randomly selected. Consequently, this question should be set read-only so the user can't actually change the proscribed random selection. If you don't wish to display this in your form, just set the select_multiple's relevant=NO to hide it. But dont delete this question!
Result
in Enketo:
in Collect:
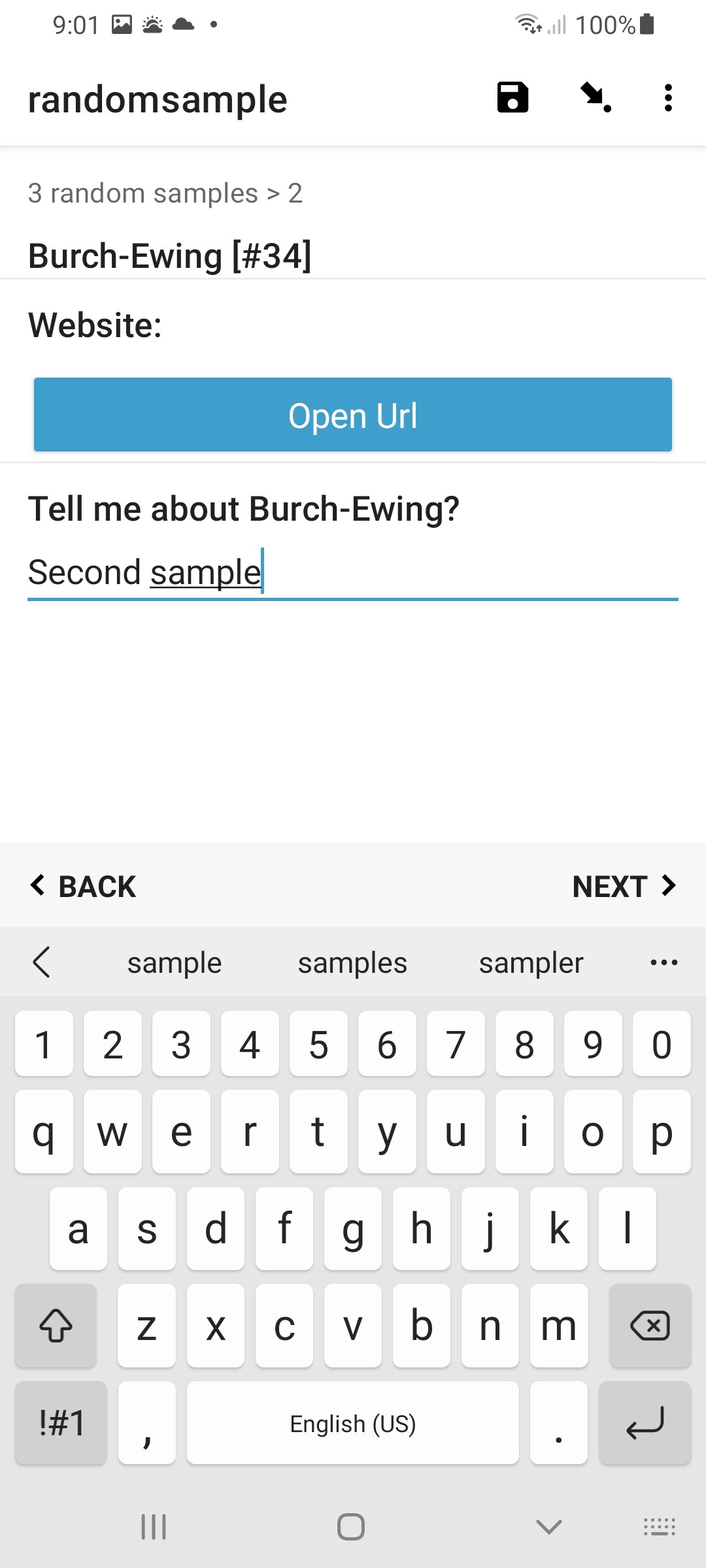
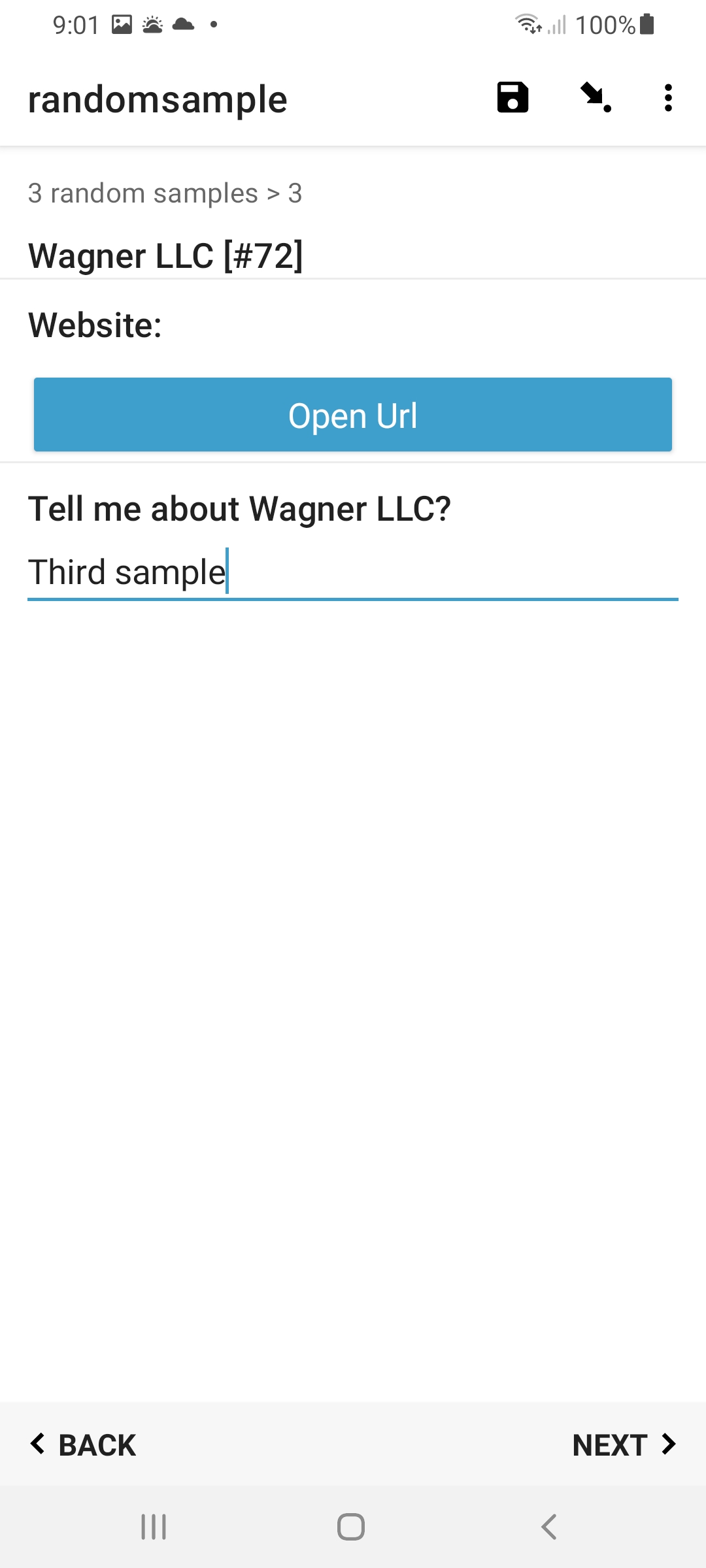
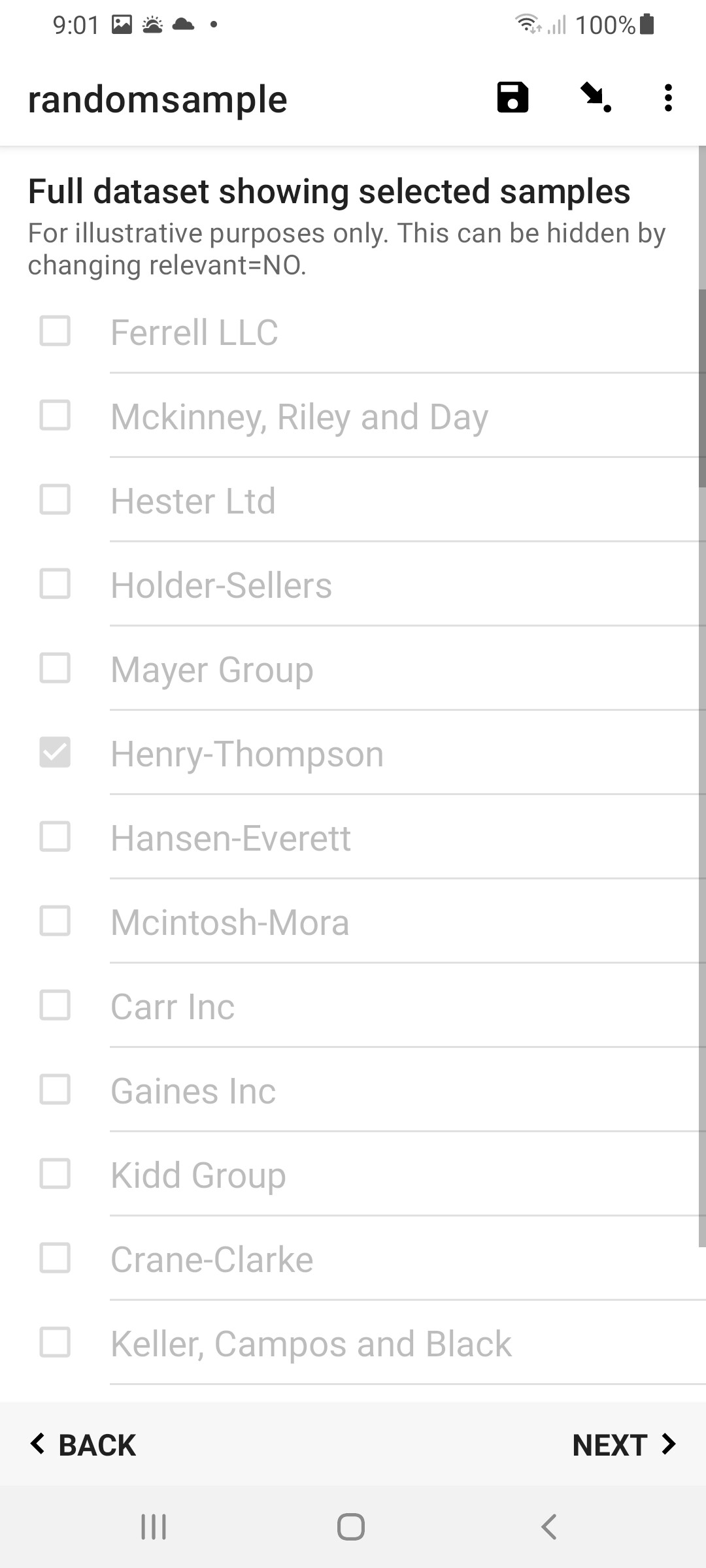

Here is the final form, with my dataset of 100 entries included.
randomsample.xlsx (23.5 KB)
Have a play around with your own dataset and let me know what you think! ![]()
Postscript
The get_size and show_sample field-list groups in my form are not terribly important; I'm just using them to display things nicely on the same screen in Collect.
As indicated, this random sampling form only works with internal instance datasets; the form as provided above unfortunately wont work against an external instance dataset (e.g. an accompanying csv attachment). But watch this space... ![]()
[UPDATE: 2023-09-17] Please see a subsequent post with an updated solution that supports external instance datasets. -Gareth]