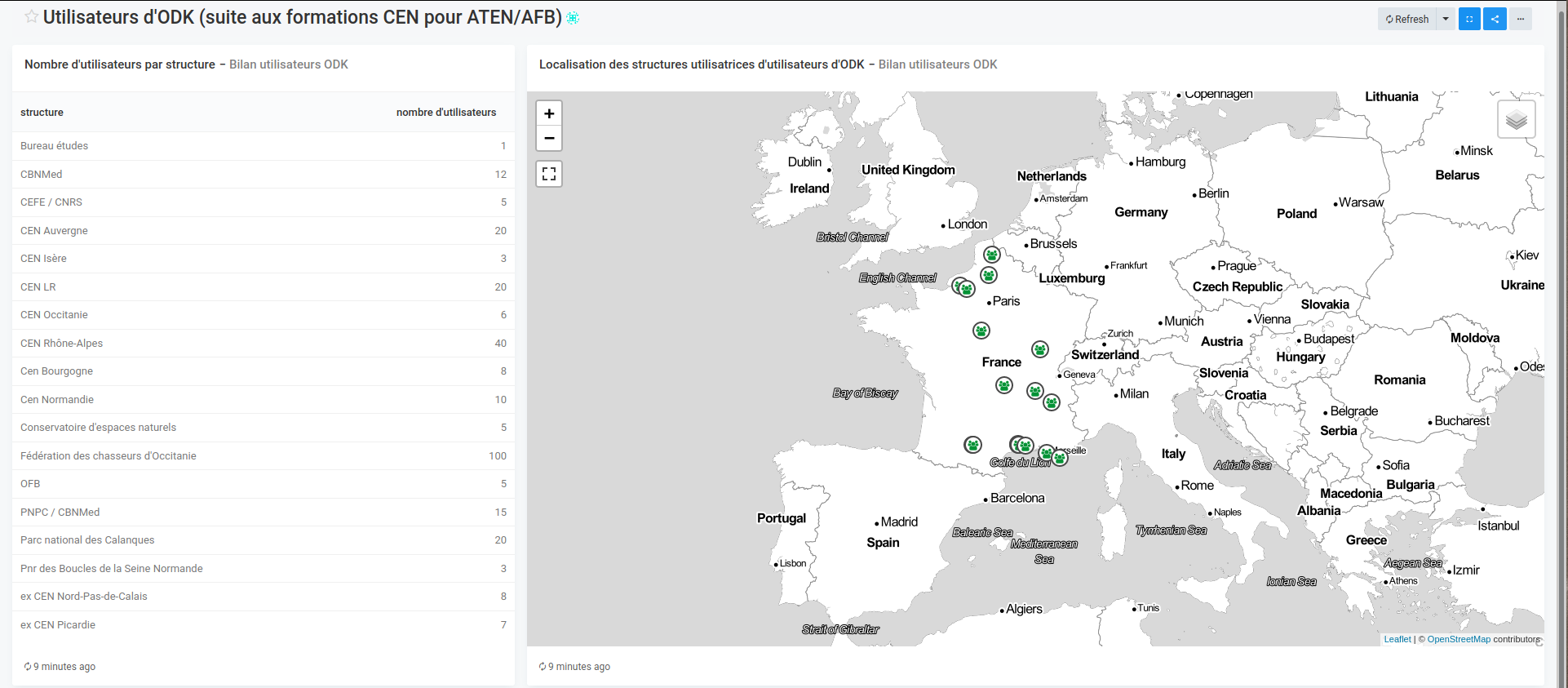
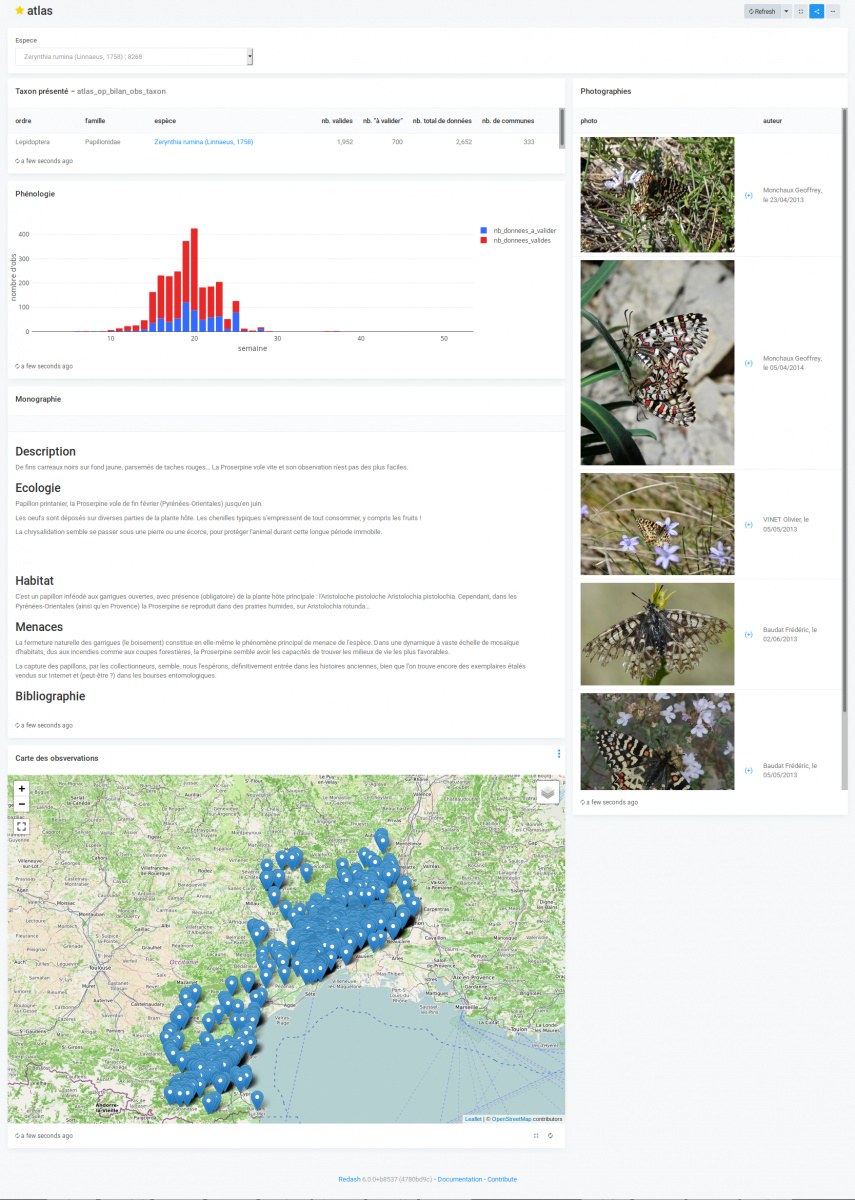
I shared my first public "web form" powered by Central's enketo capabilities, to ask people that did follow our courses, how many people are currently using ODK in their institution (Nature Conservation centric) . 22 answers in the afternoon for 171 users ! Hit the dashboards image to get updated counts.
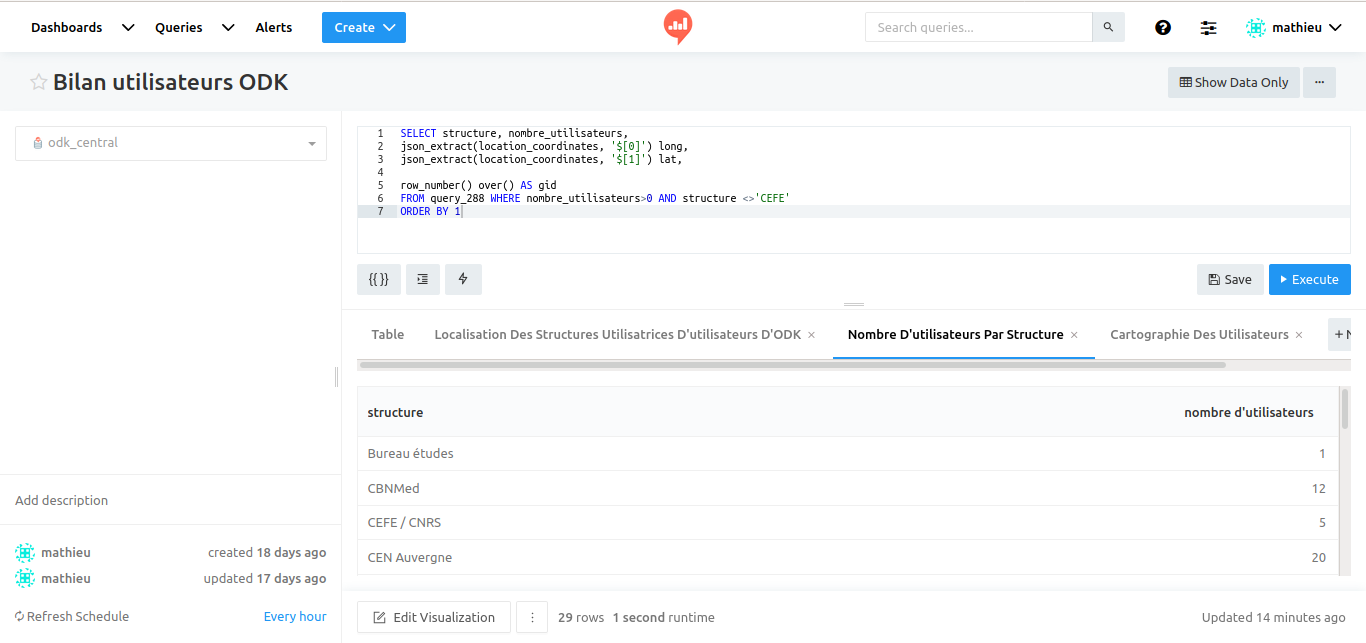
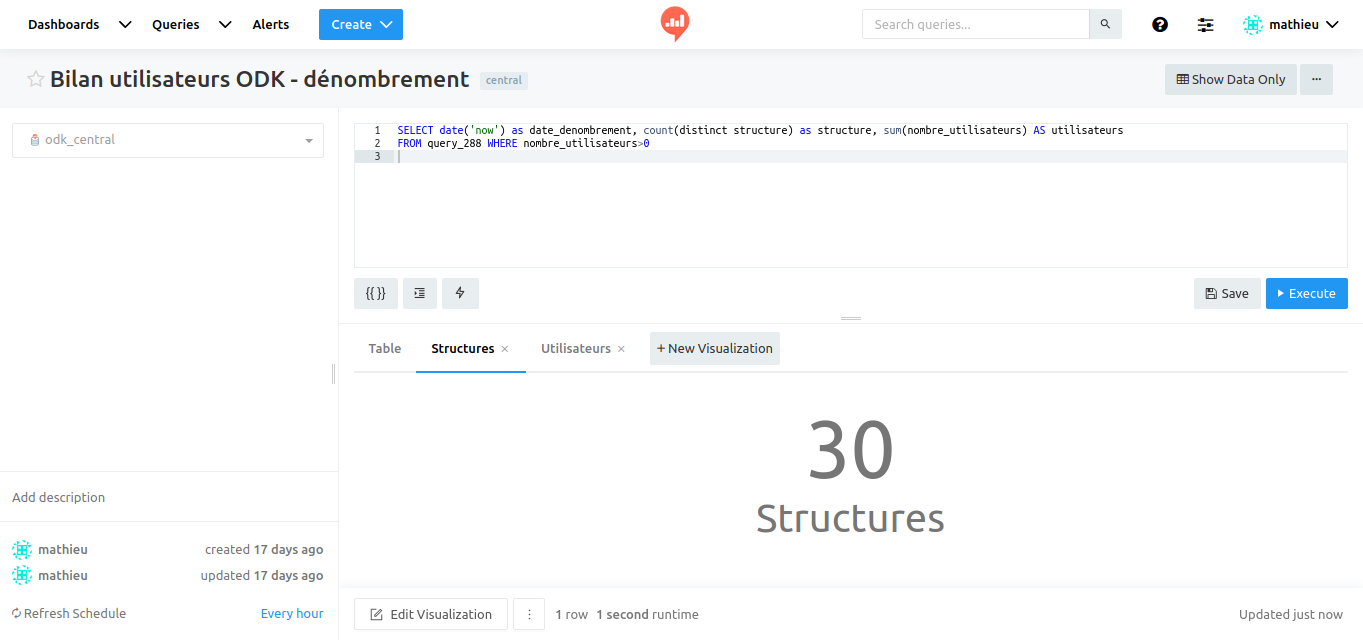
I can now already create a visualization table with for example the user count per organism
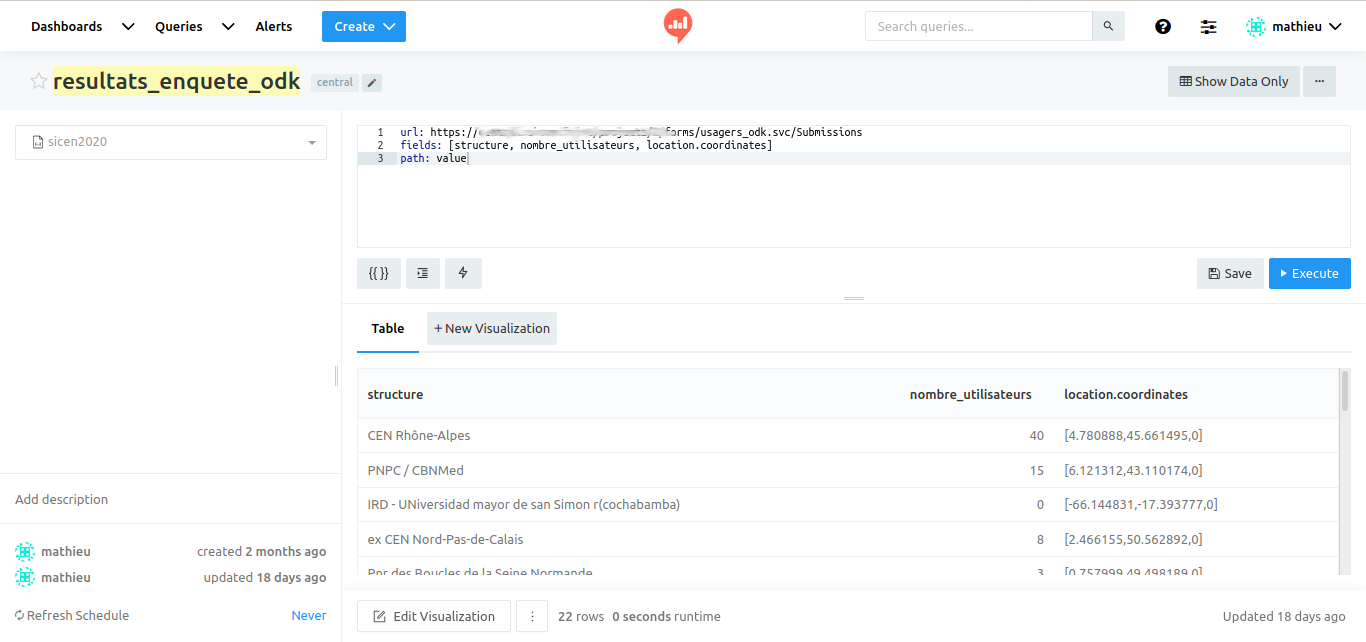
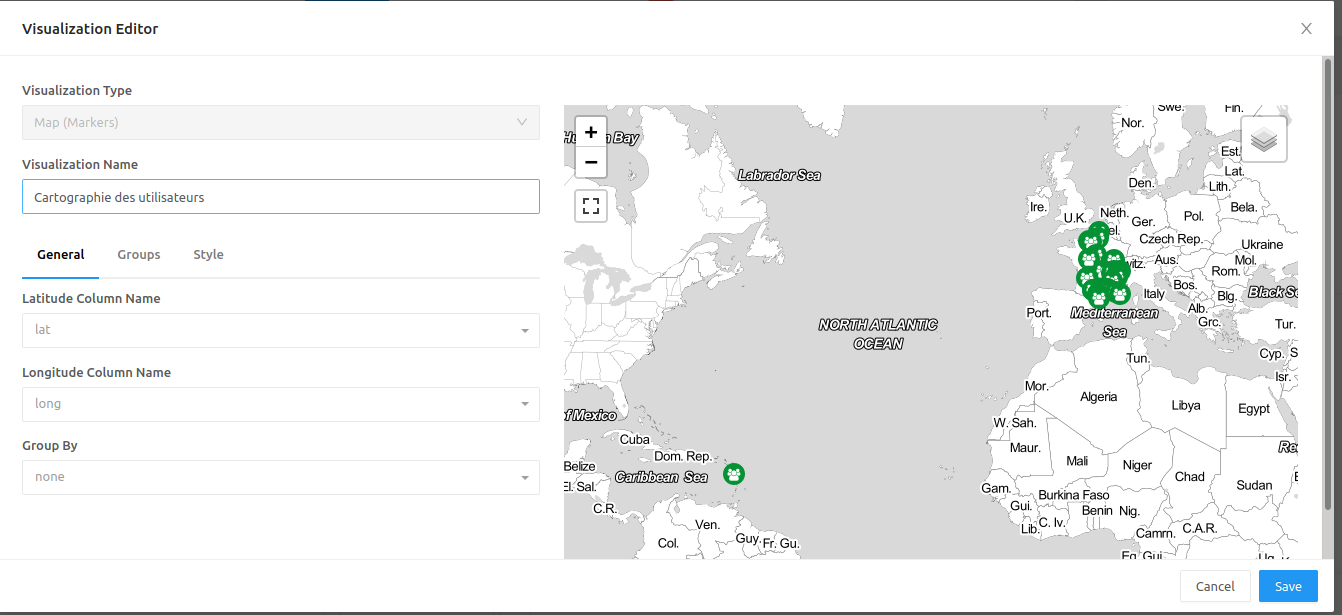
In my case, I will have to add a step to extract location coordinates from a json element.
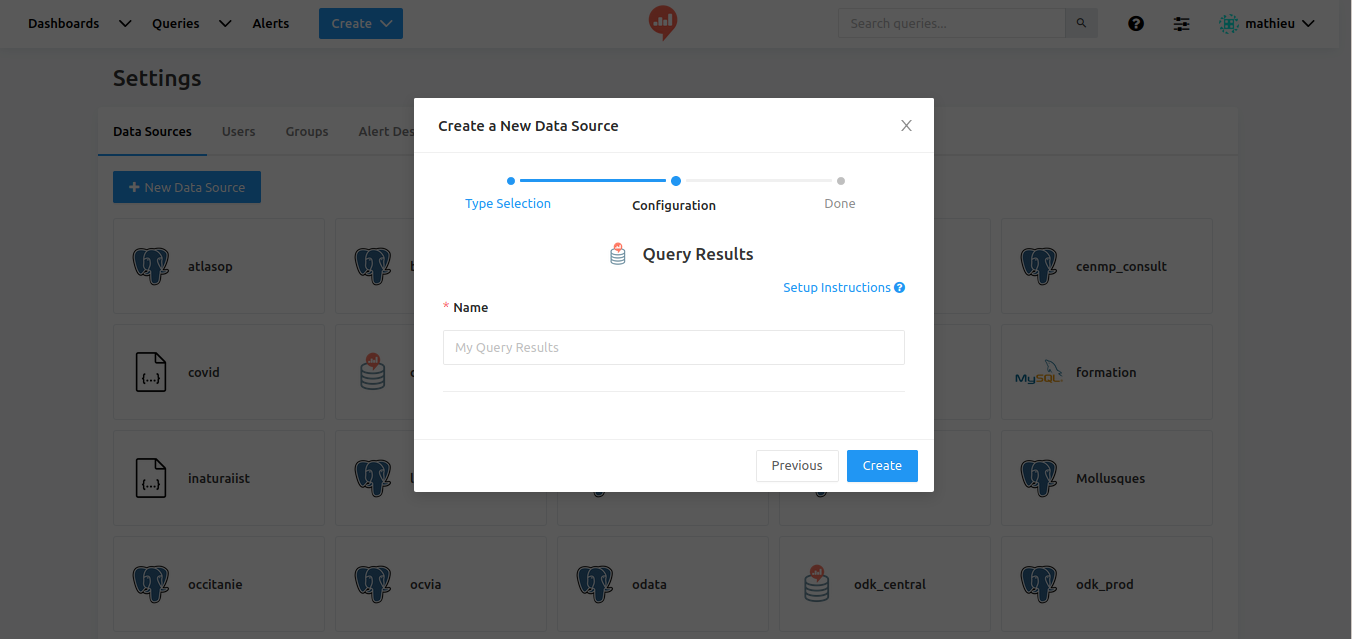
Redash offer the possibility to query a cached query result with SQL Syntax (the query result is "cached" in a sqlite database"
Now I can generate visualizations (a counter, a table, a map) and organize it into a dashboard. I that example we do not use any parameter. If it was needed, the parameters for each query in the dashboard can be set on the top of the dashboard and propagated to each query.
On big datasets, filtering Odata service will be an important step to avoid big data load, to be finally filter on the dashboard side.
Thank you for this example. This is very much along the lines of what I'm looking for. Previously I used ODK aggregate and connected directly to the underlying postgres database via metabase to achieve similar functionality. However, I've now moved to ODK central on docker, where the postgres database is hidden in docker and requires some hacking to expose for outside connections. Metabase does not support Odata feeds, so it is nice to see that Redash does. However, I see that you go back to using a postgresql datasource for your more advanced example. Is it still ultimately easier use a database datasource? For instance, my ODK forms always have repeats in them, which then require different types of sql joins for analysis. Can I do that using Odata and Redash or am I best off spending my time figuring out how to expose the ODK central postgres database for outside connections so I can just do sql queries directly?
Thank you for you interest. I did also use to directly query aggregate PostgreSQL server and I am now using Central so I had to adapt my workflows. I try different approaches, mentionned here .
Here I directly use json from cental, with a Redash tip (query result is store in a sqlite database and then you can query the result with SQL json functions) wich works pretty well.
The recent $expand option that came with central 1.2 should help as all "inner tables" are joined in the API result...
Add the ability to expand repeat groups in a single response using $expand=*. Thanks to @mattelacchiato for contributing this feature!
But now, I use an intermediate PostgreSQL database that retrieve and store all submissions from Central and transform json to database tables :
The main reason is that I integrate all the collected data in our PostgreSQL centric information system.
I will work on it in a few days to "finalize" it but for the moment it is functional and manages all our submissions over Central.
I also like matebase a lot, because of its simplicity, its dynamic community, and because it can be run as as web service on a server OR as a desktop app by simply running the jar file on a laptop.
I finally choose redash because a project needed to export charts as images and metabase did not offer it at the time.
@yanokwa ask a few hours ago on twitter what should be the next dashboard or reporting tool after GDS to integrate Central ODATA connection
Our Google Data Studio connector just shipped and it's already my favorite way to visually explore ODK datasets. What dashboarding or reporting integration should we add next? https://t.co/JtNCHGVajo
Redash and/or Metabase would be great, both are opensource and should complete a full open-source suite to collect and visualize data for SQL addict like me
I see your workaround to pull data into a new postgres database. That is probably the most logical approach for now. It also looks complicated. I would love to just plug metabase into ODK central as I did with Aggregate. I think I can expose the postgres docker port by just adding a
ports:
- "5433:5432"
to the postgres section of the docker-compose.yml. However, since entenko requires that you take down the firewall, I will need to change the password in docker-compose.yml as well. My worry is that the current password is hard coded somewhere in ODK central and thus changing it will prevent ODK central from connecting to the database.
not that much. I will probably simplify it with only one "top level function to call"
Central stores raw xml submissions that you will need to parse with PostgreSQL XML functions instead of "basic" SQL.
If you want to connect directly to the database for reporting/dashboarding purpose, you'd better create a dedicated user over the PG server, with limited privileges (connect / usage / select on database / schema / tables), instead of use a user with write access as Central's one.
I understand why you want to achieve this, I would like to do the same. But for security reasons (central's db is not exposed) I will continue to retrieve data from API and store it in a dedicated intermediate db.
Thanks for all these pointers. I keep following in your footsteps. After much fiddling, I managed to get all the fields into Redash directly from Central via the Odata. Separating lat and lon values from within a question group was especially tricky, but I got it working. Then I discover that Redash only offers core SQlite functions and there is no power function (which is essential for using tree allometry). Now looking into how to add math functions to SQlite, but of course docker adds a layer of complexity.
Apparently it would be a very easy fix because sqlite actually has advanced math functions, but they aren't part of the core sqlite. They can be activated as an option when building sqlite. But I think the issue doesn't affect other users as much because you are only limited to sqlite functions when you query from a query. Most people are querying their tables directly. Working with the Odata feed requires a two step process.