ODK has been recognized as a Global Good for Health by Digital Square at PATH. As part of the Global Goods community, we have created a public Health Interoperability Roadmap, which will sit alongside other ODK priorities (improving longitudinal data collection, making web forms more correct and performant, improving geospatial features, etc).
Unlike many of the other Global Goods, ODK is not specifically a health tool. However, it is frequently used at scale for health-related projects around the world (e.g., polio eradication, verbal autopsies).
Additionally, ODK enables a robust collection of health data in traditionally underrepresented environments (e.g. community-level, humanitarian settings) which can be of benefit to healthcare systems. In addition, non-health data can also play a crucial role in informing health systems. For example, social and environmental factors have a significant impact on health outcomes, and gathering and integrating data on these factors can provide important insights into healthcare needs and priorities.
We have outlined a living roadmap below with short and long term goals, which will continue to evolve as we learn. Through this work we will evaluate the functionality that will deliver the most value for ODK users. For the purposes of this discussion, let’s use the following definitions:
- Interoperability: ability for systems to communicate through shared standards. For example, ODK Central is interoperable with Power BI.
- Integration: connecting systems using some kind of middleware. For example, ODK Central can be integrated with RapidPro so an SMS is sent when a submission contains test_result=positive.
Living roadmap
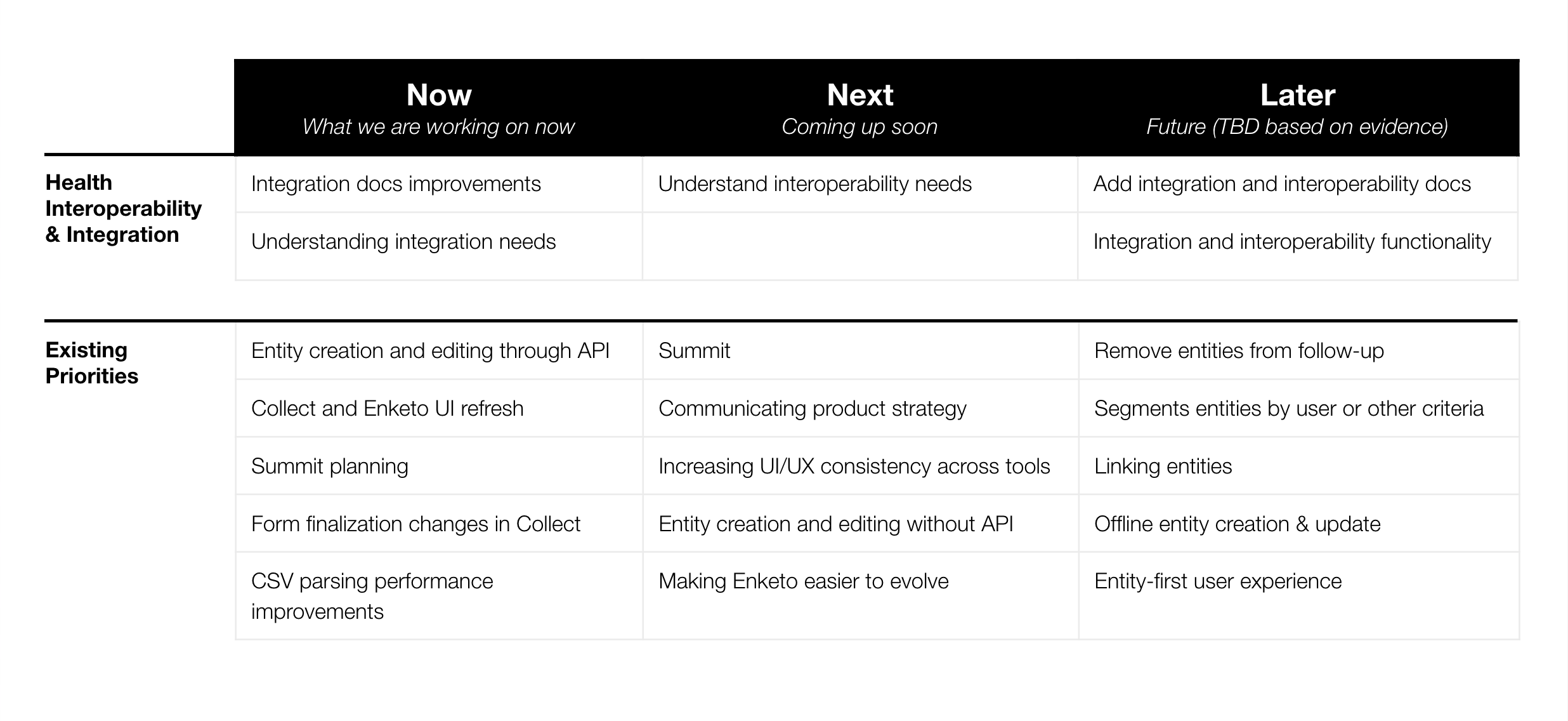
Phase 1: Known improvements (by Jun 2023)
- Create a docs page specifically about integrating with other systems
- Move existing API documentation to main docs [@Sadiqkhoja in progress]
- Add examples of building custom integrations with pyODK
Phase 2: Understand user needs (by Sep 2023)
- Talk to maintainers of other Global Goods about their users’ interoperability needs with ODK and more broadly [@LN and @Thalie in progress]
- Understand opportunities and challenges for people who are responsible for integrations:
- What functions do users see ODK as bringing to health systems?
- Which systems are ODK users currently actively integrating with (eg automatically or manually uploading data to or downloading data from)?
- Which systems would ODK users like to integrate with and why?
- What makes those integrations valuable?
- What are the barriers or concerns preventing those integrations?
- What is the ideal integration workflow?
- Understand opportunities and challenges for people responsible for interoperability:
- What are the current challenges with interoperability?
- Which systems would users like to be interoperable?
- In what ways do entities change the desirability of interoperability (e.g. because users have sources of truth for entities outside of ODK)?
- What are scenarios in which native interoperability would be desirable? Can e.g. OpenHIM be made simple enough to deploy that it replaces the need for native interoperability?
Tentative Phase 3: Improve documentation and examples around integration and interoperability (Sep 2023 and beyond)
The specifics would be determined by findings above. Some examples:
- Document strategies for using standard terminologies (e.g. https://www.hl7.org/fhir/terminologies.html)
- Document using OpenFn for workflow automation
- Build proofs of concept of converting an ODK entity representing a patient to an FHIR patient resource using OpenHIM and/or pyODK and get user feedback
- Publish narrative on how ODK could fit into the OpenHIE architecture
Tentative Phase 4: Implement functionality that lowers the barrier to integration or interoperability (Sep 2023 and beyond)
For example:
- Add support for API keys in Central. Currently interoperability systems authenticate using Web User accounts. Introducing API keys would make the separation between automated and human-initiated actions clearer and provide a way to give access to systems that don’t support Central’s authentication mechanisms.
- This could also enable direct linking to media
- Allow Central Web Users to authenticate using a configured identity provider so users have fewer identities to manage when integrating between systems (single sign-on or SSO)
- Make Central a webhook publisher (if we find a significant need for real-time integrations)
How you can help
Please let us know what you think about the approach we propose and whether there are additional user needs or challenges we should consider and why. I’ll keep this post updated according to your suggestions and comments.
If you have specific answers to some of the research questions outlined, please answer here as well!
People I think will be particularly interested:
- @Sjlver has aggregated resources on connecting to DHIS2 and @saad was also involved in that thread
- @delcroip’s broad interoperability experience helped shape this draft
- @chrissyhroberts, @dr_michaelmarks, @aurdipas