I've been playing a bit with OpenAI's Whisper transcription library. The open source library is relatively small and can be run on simple hardware. It's highly accurate for English even with relatively small models. It can also do translation and there's good information on how likely it is to be correct for each language on the Github page.
I put together a small script that can be used to update submissions of a form with a transcript of an audio file from that submission. This approach would be useful in contexts where it's helpful to have the transcript in Central so that it can be part of the submission review process, for example. If you don't use Central as your primary source of truth, you could do this transcription after downloading your full dataset (as part of your Extract-Transform-Load pipeline).
For projects with relatively short audio files and low submission volume (<1000 per day), it should be fine to run this on the same host as Central with a cron job that runs outside of data collection hours. For large submission volume it may be more cost effective and robust to use a paid API (e.g. OpenAI's).
I used a form with an audio field and a text field for the transcript. I don't want data collectors to see the text field so I included a hidden field that makes the transcript non-relevant. The update script injects the transcript in the text field and changes the value of the hidden field so that the transcript is visible when viewing or editing the submission. I left the text field editable so that a person could further edit the transcript. It could alternatively be made read-only. The form: recordings.xlsx (9.6 KB)
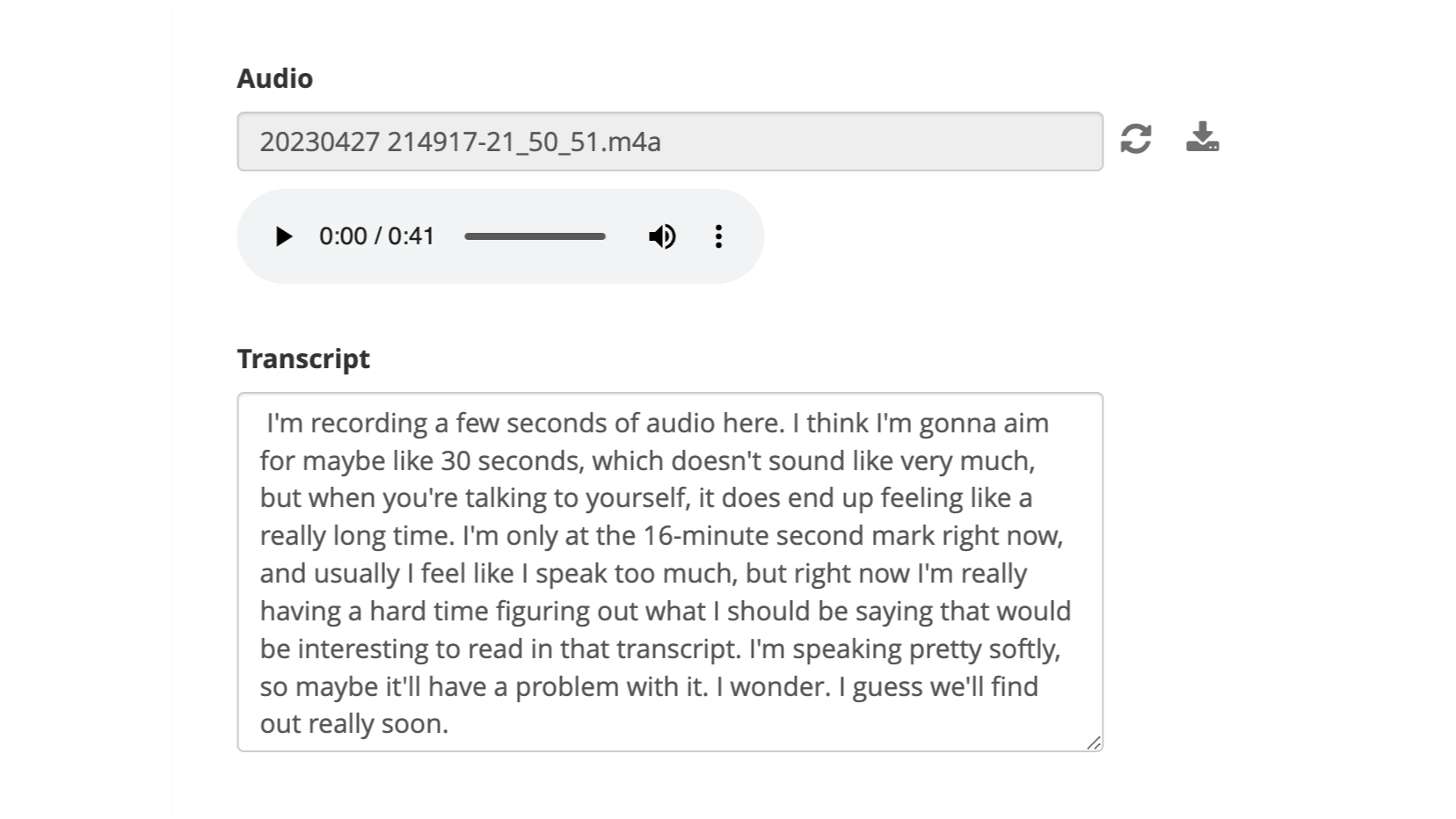
The script is not extensively tested and doesn't do robust error handling. I'm happy to answer any questions and continue to iterate on it if there's interest. Feel free to take the ideas and make it your own!
import logging
import os
import uuid
import whisper
from logging.handlers import RotatingFileHandler
from pyodk.client import Client
from xml.etree import ElementTree as ET
FORM_ID = "recordings"
LOG = "transcriber.log"
CLIENT = Client()
LOGGER = logging.getLogger("transcriber")
TRANSCRIPTION_MODEL = whisper.load_model("base.en")
def configure_logger(filename):
LOGGER.setLevel(logging.INFO)
handler = RotatingFileHandler(filename, maxBytes=5 * 1024 * 1024, backupCount=2)
formatter = logging.Formatter(fmt='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p')
handler.setFormatter(formatter)
LOGGER.addHandler(handler)
logging.basicConfig(level=logging.INFO, format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p')
configure_logger(LOG)
LOGGER.info("##### Running #####")
# Download submissions in the 'received' review state (not yet updated by this script)
new_submissions = CLIENT.submissions.get_table(form_id="recordings", filter=f"__system/reviewState eq null")["value"]
new_submissions = {sub['__id']: sub['audio'] for sub in new_submissions}
for instanceid in new_submissions:
audio_bytes = CLIENT.get(f'/projects/{CLIENT.config.central.default_project_id}/forms/{FORM_ID}/submissions/{instanceid}/attachments/{new_submissions[instanceid]}')
try:
with open(new_submissions[instanceid], 'wb') as audio_file:
audio_file.write(audio_bytes.content)
LOGGER.info(f"Transcribing {instanceid}")
transcript = TRANSCRIPTION_MODEL.transcribe(new_submissions[instanceid])['text']
finally:
os.remove(new_submissions[instanceid])
submission = CLIENT.get(f'/projects/{CLIENT.config.central.default_project_id}/forms/{FORM_ID}/submissions/{instanceid}.xml').text
root = ET.fromstring(submission)
root.find('show_transcript').text = 'y'
transcript_node = ET.SubElement(root, 'transcript')
transcript_node.text = transcript
meta_node = root.find('meta')
instanceid_node = meta_node.find('instanceID')
deprecatedid_node = meta_node.find('deprecatedID')
if deprecatedid_node is None:
deprecatedid_node = ET.SubElement(meta_node, 'deprecatedID')
deprecatedid_node.text = instanceid_node.text
instanceid_node.text = 'uuid:' + str(uuid.uuid4())
try:
xml = ET.tostring(root)
except Exception as e:
LOGGER.error(e)
else:
CLIENT.submissions.edit(instanceid, xml, form_id=FORM_ID, comment="Transcribed by Whisper v20230314 with base.en")
if len(new_submissions) == 0:
LOGGER.info("No new submissions")