1. What is the general goal of the feature?
Better support workflows that are centered around an entity which is visited one or more times. See the data collector workflows documentation for examples of how users address this need currently.
2. What are some example use cases for this feature?
There is a dedicated topic that links to use cases and related conversations over time. Thanks to everyone who has been involved in these conversations.
We will be adding the following concepts to Central and then over time exposing them more explicitly in Collect:
- Entity: a person, place or thing that Forms can be about. Created, updated and archived by one or more Forms.
- Entity Properties: values representing the current state of an Entity. Defined by Forms and populated by Submissions.
- Dataset: a collection of Entities of the same type.
The implementation will start on the server side and will eventually lead to changes to Collect. A rough mockup of the data collector experience we will be working towards:
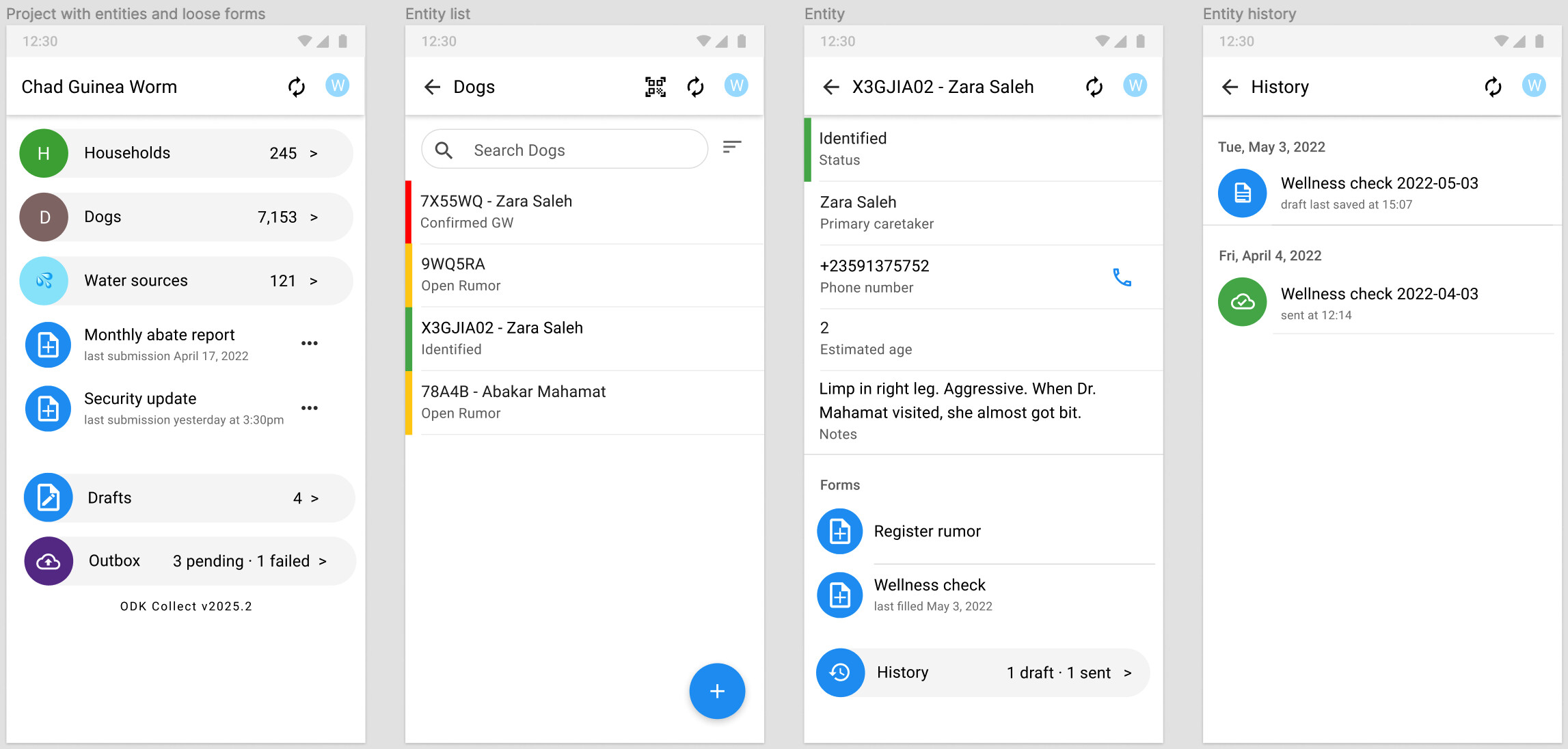
Mockup of Collect user interface re-oriented towards entities. This is an example for a guinea worm eradication project that needs to track dogs (vectors of guinea worms), households (may be responsible for dogs), water sources (which need to be treated against guinea worms), etc.
The first screen shows different Datasets (households, dogs, water sources) as well as Forms not connected to Entities (Monthly Abate Report, Security Update). The second screen shows an entity listing for the dogs Dataset. The third screen shows a specific dog Entity, its Entity Properties, and the Forms that can be filled out about it.
Entities:
- Have at minimum a unique identifier
- See X3GJIA02 above which might be an identifier scanned from a barcode
- May optionally have other properties
- See status, primary caretaker, etc for X3GJIA02 above
- Expose all their properties to forms that are filled out about them for optional referencing
- For example, the “Wellness check” form above might use the primary caretaker name as part of question text
- May get their properties set or updated by forms
- For example, the “Register rumor” form above might change the dog’s status
- Expose all their properties to clients for use in list/map/summary views
- For example, some properties of each dog are shown in the entity list above
- Have a flat property list (no groups, no repeats)
- Properties represent the state of a single entity at the current point in time
- May optionally be created from a form definition
- For example, the + “floating action button” at the bottom right of the form listing screen launches an entity creation form
- May optionally be archived by one or more form definitions
- For example, a “Register death” form for dogs might archive a dog, making it unavailable to field devices (but still visible on the server)
This model provides a layer on top of existing ODK concepts and functionality.
Initially, Datasets in Central will behave like server-managed CSV external datasets and there will be no changes to Collect or Enketo. We expect that the next release of Central (ETA: Fall 2022) will include:
- Experimental form specification for declaring that Submissions of a Form create Entities in a particular Dataset (XML-only, XLSForm will come after)
- Entity creation on Submission approval
- Ability to attach a Central-managed Dataset instead of an uploaded CSV file to a form that declares a CSV external dataset
Initially these workflows will require a server round trip: a submission will have to be processed from Central and Collect/Enketo will need to get a CSV update. Eventually, Entity creation and update will happen entirely offline.
Q: This is amazing! When can I use it?
We aim to have the initial Central functionality outlined above released by the end of fall 2022. We will conduct field tests and focus groups with that alpha functionality before publishing a formal spec. This initial functionality will only enable Dataset and Entity creation (not update or archive) and only on submission approval, so it will be most useful for projects that have a registration step and a single follow-up. We will then progressively layer on functionality to support more complex and more dynamic workflows.
Q: This is terrible! ODK serves my needs today. Is my life about to get more complicated?
No. Our goal is to make these new features almost entirely invisible to users who are well-served by ODK today.
Q: Is this case management?
Case management involves coordinating services to bring some kind of case to closure. Examples of cases would be “a person with HIV”, “a pregnant woman”, “a refugee needing housing”. We expect that the tools we have outlined will eventually support many complex case management needs. We use the term “entity” because it is more generic and easier to reason about in industries where “case management” is not typically used (e.g. forestry).
Q: How was this model designed and what alternatives were considered?
The entity-based data collection working group worked through many decision points to get to this model. Some key ones:
- Forms and Entities are distinct concepts. One notable alternative would be to only have the Form concept and to provide queriable access to all submissions. The downside is that getting the most recent state would often require complex queries across submissions from multiple forms. Entities store the most recent state, which is often enough to drive workflows.
- Form Submissions continue to be the way data goes from a client to a server. There are alternatives like immediately syncing on a per-field basis. Keeping the submission model means more existing mental models and code can be reused and older clients will work with most of the system.
- Entity creation, update, archive are configured in form definitions. An alternative would be to let servers manage that process. Adding to the form definition has two major benefits: it lets form designers think about all aspects of a form field at once and it ensures greater portability between compatible systems.
Q: What can I do to help?
Share your use cases, provide feedback on proposals, try out new releases.
Please also consider using ODK Cloud for your next data collection project. It’s what pays for the development of new functionality.